Train Spoken Digit Recognition Network Using Out-of-Memory Audio Data
This example trains a spoken digit recognition network on out-of-memory audio data using a transformed datastore. In this example, you apply a random pitch shift to audio data used to train a convolutional neural network (CNN). For each training iteration, the audio data is augmented using the audioDataAugmenter object and then features are extracted using the audioFeatureExtractor object. The workflow in this example applies to any random data augmentation used in a training loop. The workflow also applies when the underlying audio data set or training features do not fit in memory.
Data
Download the Free Spoken Digit Data Set (FSDD) [1]. FSDD consists of 2000 recordings of four speakers saying the numbers 0 through 9 in English.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","FSDD.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) dataset = fullfile(dataFolder,"FSDD");
Create an audioDatastore that points to the dataset.
ads = audioDatastore(dataset,IncludeSubfolders=true,OutputDataType="single");Decode the file names to set the labels on the datastore. Display the classes and the number of examples in each class.
labels = filenames2labels(ads,ExtractBefore="_");
summary(labels) 0 200
1 200
2 200
3 200
4 200
5 200
6 200
7 200
8 200
9 200
Split the FSDD into training and test sets. Allocate 90% of the data to the training set and retain 10% for the test set. You use the training set to train the model and the test set to validate the trained model.
idxs = splitlabels(labels,0.9,"randomized");
adsTrain = subset(ads,idxs{1});
adsTest = subset(ads,idxs{2});
labelsTrain = labels(idxs{1});
labelsTest = labels(idxs{2});
classes = unique(labelsTrain);Reduce Training Dataset
To train the network with the entire dataset and achieve the highest possible accuracy, set speedupExample to false. To run this example quickly, set speedupExample to true.
speedupExample =false; if speedupExample adsTrain = subset(adsTrain,1:90:numel(labelsTrain)); adsTest = subset(adsTest,1:10:numel(labelsTest)); labelsTrain = labelsTrain(1:90:numel(labelsTrain)); labelsTest = labelsTest(1:10:numel(labelsTest)); end
Transformed Training Datastore
Data Augmentation
Augment the training data by applying pitch shifting with an audioDataAugmenter object.
Create an audioDataAugmenter. The augmenter applies pitch shifting on an input audio signal with a 0.5 probability. The augmenter selects a random pitch shifting value in the range [–12 12] semitones.
augmenter = audioDataAugmenter( ... PitchShiftProbability=0.5, ... SemitoneShiftRange=[-12 12], ... TimeShiftProbability=0, ... VolumeControlProbability=0, ... AddNoiseProbability=0);
Set custom pitch-shifting parameters. Use identity phase locking and preserve formants using spectral envelope estimation with 30th order cepstral analysis.
setAugmenterParams(augmenter,"shiftPitch",LockPhase=true,PreserveFormants=true,CepstralOrder=30);Create a transformed datastore that applies data augmentation to the training data.
fs = 8000;
adsAugTrain = transform(adsTrain,@(y)deal(augment(augmenter,y,fs).Audio{1}));Mel Spectrogram Feature Extraction
The CNN accepts mel-frequency spectrograms.
Define parameters used to extract mel-frequency spectrograms. Use 220 ms windows with 10 ms hops between windows. Use a 2048-point DFT and 40 frequency bands.
frameDuration = 0.22; frameLength = round(frameDuration*fs); hopDuration = 0.01; hopLength = round(hopDuration*fs); segmentLength = 8192; numBands = 40; fftLength = 2048;
Create an audioFeatureExtractor object to compute mel-frequency spectrograms from input audio signals.
afe = audioFeatureExtractor( ... melSpectrum=true, ... SampleRate=fs, ... Window=hamming(frameLength,"periodic"), ... OverlapLength=(frameLength - hopLength), ... FFTLength=fftLength);
Set the parameters for the mel-frequency spectrogram.
setExtractorParameters(afe,"melSpectrum", ... NumBands=numBands, ... FrequencyRange=[50 fs/2], ... WindowNormalization=true, ... ApplyLog=true);
Create a transformed datastore that computes mel-frequency spectrograms from pitch-shifted audio data. The supporting function, getSpeechSpectrogram, standardizes the recording length and normalizes the amplitude of the audio input. getSpeechSpectrogram uses the audioFeatureExtractor object to obtain the log-based mel-frequency spectrograms.
adsSpecTrain = transform(adsAugTrain,@(x)getSpeechSpectrogram(x,afe,segmentLength));
Training Labels
Use an arrayDatastore to hold the training labels.
labelsTrain = arrayDatastore(labelsTrain);
Combined Training Datastore
Create a combined datastore that points to the mel-frequency spectrogram data and the corresponding labels.
tdsTrain = combine(adsSpecTrain,labelsTrain);
Validation Data
The validation dataset fits into memory. Precompute validation features.
adsTestT = transform(adsTest,@(x){getSpeechSpectrogram(x,afe,segmentLength)});
XTest = readall(adsTestT);
XTest = cat(4,XTest{:});Define CNN Architecture
Construct a small CNN as an array of layers. Use convolutional and batch normalization layers, and downsample the feature maps using max pooling layers. To reduce the possibility of the network memorizing specific features of the training data, add a small amount of dropout to the input to the last fully connected layer.
sz = size(XTest);
specSize = sz(1:2);
imageSize = [specSize 1];
numClasses = numel(classes);
dropoutProb = 0.2;
numF = 12;
layers = [
imageInputLayer(imageSize,Normalization="none")
convolution2dLayer(5,numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,2*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2)
dropoutLayer(dropoutProb)
fullyConnectedLayer(numClasses)
softmaxLayer
];Set the hyperparameters to use in training the network. Use a mini-batch size of 128 and a learning rate of 1e-4. Specify 'adam' optimization. To use the parallel pool to read the transformed datastore, set DispatchInBackground to true. For more information, see trainingOptions (Deep Learning Toolbox).
miniBatchSize = 128; options = trainingOptions("adam", ... Metrics="accuracy", ... InitialLearnRate=1e-4, ... MaxEpochs=40, ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.1, ... LearnRateDropPeriod=30, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... ValidationData={XTest,labelsTest}, ... ValidationFrequency=ceil(2*numel(adsTrain.Files)/miniBatchSize), ... ValidationPatience=5, ... ExecutionEnvironment="auto", ... OutputNetwork="best-validation");
Train the network by passing the transformed training datastore to trainnet.
trainedNet = trainnet(tdsTrain,layers,"crossentropy",options);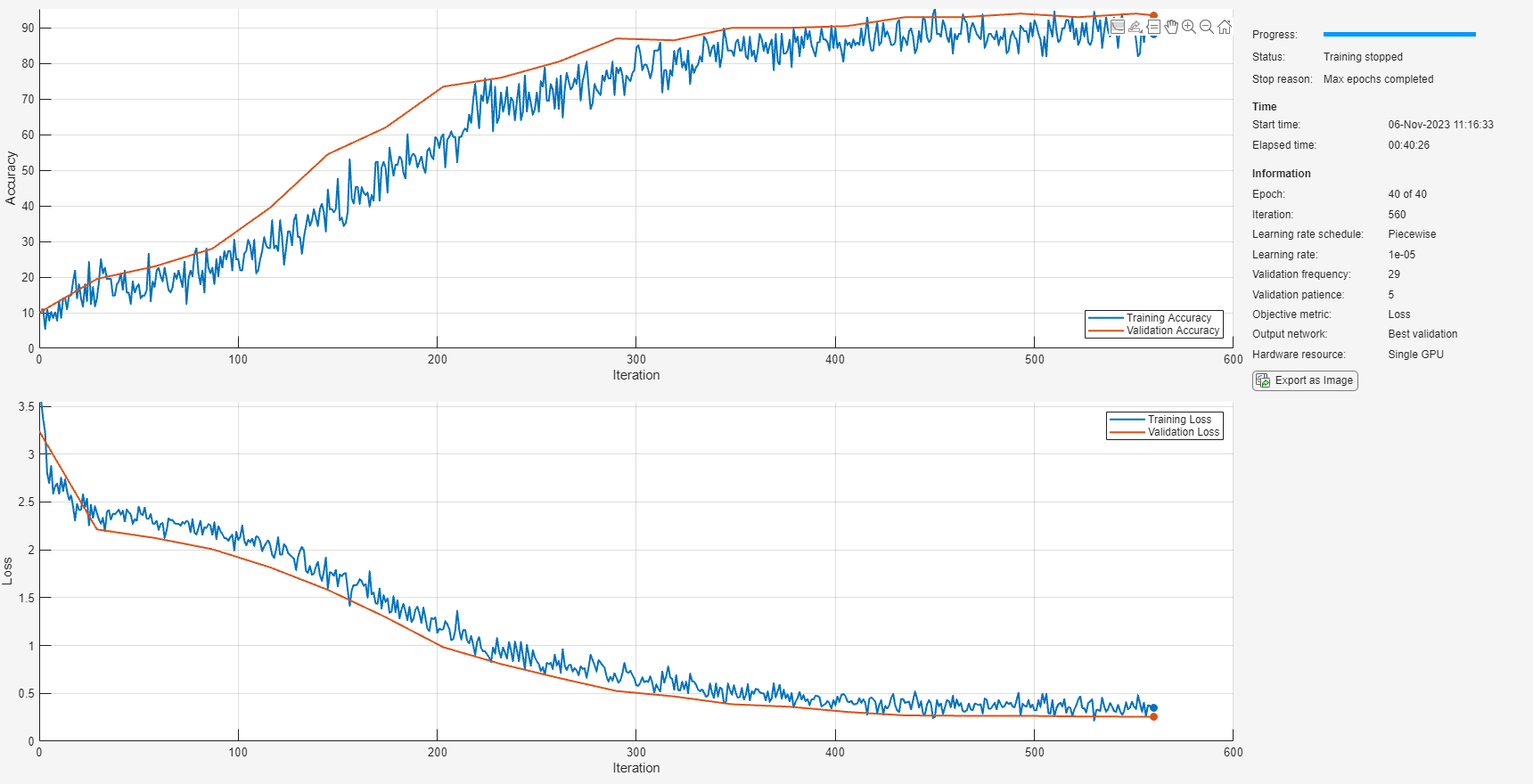
Use the trained network to predict the digit labels for the test set.
probs = minibatchpredict(trainedNet,XTest); Ypredicted = scores2label(probs,classes); cnnAccuracy = mean(Ypredicted==labelsTest)*100
cnnAccuracy = 93.5000
Summarize the performance of the trained network on the test set with a confusion chart. Display the precision and recall for each class by using column and row summaries. The table at the bottom of the confusion chart shows the precision values. The table to the right of the confusion chart shows the recall values.
figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]); confusionchart(labelsTest,Ypredicted, ... Title="Confusion Chart for DCNN", ... ColumnSummary="column-normalized",RowSummary="row-normalized");

Supporting Functions
Get Speech Spectrograms
function X = getSpeechSpectrogram(x,afe,segmentLength) % getSpeechSpectrogram(x,afe,segmentLength) computes a speech spectrogram for the % signal x using the audioFeatureExtractor afe. x = resize(x,segmentLength,Side="both"); x = x./max(abs(x)); X = extract(afe,x).'; end
References
[1] Jakobovski. “Jakobovski/Free-Spoken-Digit-Dataset.” GitHub, May 30, 2019. https://github.com/Jakobovski/free-spoken-digit-dataset.