Levinson-Durbin
Solve linear system of equations using Levinson-Durbin recursion

Libraries:
DSP System Toolbox /
Estimation /
Linear Prediction /
Linear System Solvers
DSP System Toolbox /
Math Functions /
Matrices and Linear Algebra /
Linear System Solvers
Description
The Levinson-Durbin block solves the nth-order system of linear equations
Ra = b
in the cases where:
R is a Hermitian, positive-definite, Toeplitz matrix.
b is identical to the first column of R shifted by one element and with the opposite sign.
Examples

Analysis and Synthesis of Speech
A speech signal is usually represented in digital format, which is a sequence of binary bits. For storage and transmission applications, it is desirable to compress a signal by representing it with as few bits as possible, while maintaining its perceptual quality. Quantization is the process of representing a signal with a reduced level of precision. If you decrease the number of bits allocated for the quantization of your speech signal, the signal is distorted and the speech quality degrades.
Ports
Input
Output
Parameters
Main Tab
Specify the solution representation of Ra = b to output:
Polynomial coefficients (
A) — For each channel, port A outputsA =[1 a(2) a(3) ... a(n+1)], the solution to the Levinson-Durbin equation. A has the same dimension as the input. You can also view the elements of each output channel as the coefficients of an nth-order autoregressive (AR) process.Reflection coefficients (
K) — For each channel, port K outputsK =[k(1) k(2) ... k(n)], which contains n reflection coefficients and has the same dimension as the input, less one element. A scalar input channel causes an error when you selectK. You can use reflection coefficients to realize a lattice representation of the AR process described later in this page.Both model coefficients and reflection coefficients (
A and K) — The block outputs both representations at their respective ports. A scalar input channel causes an error when you selectA and K.
When the input is a scalar or row vector, you must set this parameter
to A.
Select this parameter to output the prediction error power for each channel at port P.
When you select this check box and the first element of the input,
r(1), is zero, the block outputs the following
vectors, as appropriate:
A = [1 zeros(1,n)]K = [zeros(1,n)]P = 0
When you clear this check box, the block outputs a vector of NaNs for each channel
whose r(1) element is zero. In general, an input with
r(1) = 0 is invalid because it
does not construct a positive-definite matrix R.
Often, however, blocks receive zero-valued inputs at the start of a
simulation. The check box allows you to avoid propagating
NaNs during this period.
Data Types Tab
Note
Floating-point inheritance takes precedence over the data type settings defined on this pane. When inputs are floating point, the block ignores these settings, and all internal data types are floating point.
Specify the rounding mode for fixed-point operations as one of the following:
FloorCeilingConvergentNearestRoundSimplestZero
For more details, see rounding mode.
When you select this parameter, the block saturates the result of its
fixed-point operation. When you clear this parameter, the block wraps
the result of its fixed-point operation. For details on
saturate and wrap, see overflow
mode for fixed-point operations.
Specify the product output data type as Inherit: Same as
input or a numeric type. See Fixed-Point Data Types and Multiplication Data Types for illustrations depicting the
use of the product output data type in this block. You can set it
to:
A rule that inherits a data type, for example,
Inherit: Same as inputAn expression that evaluates to a valid data type, for example,
fixdt(1,16,0)
Click the Show data type assistant button
![]() to display the Data Type
Assistant, which helps you set the Product
output parameter.
to display the Data Type
Assistant, which helps you set the Product
output parameter.
See Specify Data Types Using Data Type Assistant (Simulink) for more information.
Specify the accumulator data type as Inherit: Same as
input, Inherit: Same as product
output, or a numeric type. See Fixed-Point Data Types for
illustrations depicting the use of the accumulator data type in this
block. You can set it to:
A rule that inherits a data type, for example,
Inherit: Same as inputA rule that inherits a data type, for example,
Inherit: Same as product outputAn expression that evaluates to a valid data type, for example,
fixdt(1,16,0)
Click the Show data type assistant button
![]() to display the Data Type
Assistant, which helps you set the
Accumulator parameter.
to display the Data Type
Assistant, which helps you set the
Accumulator parameter.
See Specify Data Types Using Data Type Assistant (Simulink) for more information.
Specify the polynomial coefficients (A) data type
as a numeric type. See Fixed-Point Data Types for
illustrations depicting the use of the A data type in this block. You
can set it to an expression that evaluates to a valid data type, for
example, fixdt(1,16,10).
Click the Show data type assistant button
![]() to display the Data Type
Assistant, which helps you set the A
parameter.
to display the Data Type
Assistant, which helps you set the A
parameter.
See Specify Data Types Using Data Type Assistant (Simulink) for more information.
Specify the reflection coefficients (K) data type
as a numeric type. See Fixed-Point Data Types for
illustrations depicting the use of the K data type in this block. You
can set it to an expression that evaluates to a valid data type, for
example, fixdt(1,16,10).
Click the Show data type assistant button
![]() to display the Data Type
Assistant, which helps you set the K
parameter.
to display the Data Type
Assistant, which helps you set the K
parameter.
See Specify Data Types Using Data Type Assistant (Simulink) for more information.
Specify the prediction error power (P) data type as
Inherit: Same as input or a numeric type.
See Fixed-Point Data Types for
illustrations depicting the use of the P data type in this block. You
can set it to:
A rule that inherits a data type, for example,
Inherit: Same as inputAn expression that evaluates to a valid data type, for example,
fixdt(1,16,0)
Click the Show data type assistant button
![]() to display the Data Type
Assistant, which helps you set the P
parameter.
to display the Data Type
Assistant, which helps you set the P
parameter.
See Specify Data Types Using Data Type Assistant (Simulink) for more information.
Specify the minimum values that the polynomial coefficients,
reflection coefficients, or prediction error power should have. The
default value is [] (unspecified). Simulink® uses this value to perform:
Parameter range checking (see Specify Minimum and Maximum Values for Block Parameters (Simulink))
Automatic scaling of fixed-point data types
Specify the maximum values that the polynomial coefficients,
reflection coefficients, or prediction error power should have. The
default value is [] (unspecified). Simulink uses this value to perform:
Parameter range checking (see Specify Minimum and Maximum Values for Block Parameters (Simulink))
Automatic scaling of fixed-point data types
Block Characteristics
Data Types |
|
Direct Feedthrough |
|
Multidimensional Signals |
|
Variable-Size Signals |
|
Zero-Crossing Detection |
|
More About
The diagrams in this section show the data types used within the Levinson-Durbin block for fixed-point signals.
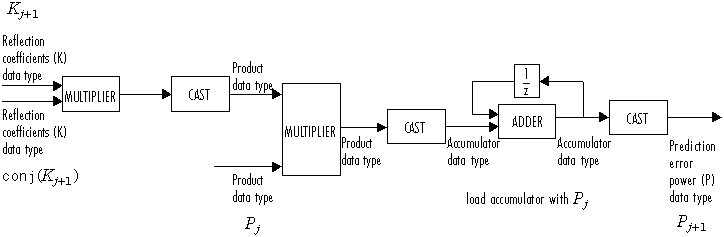
After initialization the block performs n updates. At the (j+1) update,
The following diagram displays the fixed-point data types used in this calculation:

The block then updates the reflection coefficients K according to
The block then updates the prediction error power P according to
The next diagram displays the fixed-point data types used in this calculation:

The polynomial coefficients A are then updated according to
This diagram displays the fixed-point data types used in this calculation:
Algorithms
The algorithm requires O(n2) operations for each input channel. This implementation is therefore much more efficient for large n than standard Gaussian elimination, which requires O(n3) operations per channel.
References
[1] Golub, G. H. and C. F. Van Loan. Sect. 4.7 in Matrix Computations. 3rd ed. Baltimore, MD: Johns Hopkins University Press, 1996.
[2] Ljung, L. System Identification: Theory for the User. Englewood Cliffs, NJ: Prentice Hall, 1987. Pgs. 278–280.
[3] Kay, Steven M. Modern Spectral Estimation: Theory and Application. Englewood Cliffs, NJ: Prentice Hall, 1988.
Extended Capabilities
Version History
Introduced before R2006a