ClassificationPartitionedGAM
Cross-validated generalized additive model (GAM) for classification
Description
ClassificationPartitionedGAM is a set of generalized additive
models trained on cross-validated folds. Estimate the quality of the cross-validated
classification by using one or more kfold functions:
kfoldPredict, kfoldLoss,
kfoldMargin, kfoldEdge, and
kfoldfun.
Every kfold object function uses models trained on training-fold (in-fold) observations to predict the response for validation-fold (out-of-fold) observations. For example, suppose you cross-validate using five folds. The software randomly assigns each observation into five groups of equal size (roughly). The training fold contains four of the groups (roughly 4/5 of the data), and the validation fold contains the other group (roughly 1/5 of the data). In this case, cross-validation proceeds as follows:
The software trains the first model (stored in
CVMdl.Trained{1}) by using the observations in the last four groups, and reserves the observations in the first group for validation.The software trains the second model (stored in
CVMdl.Trained{2}) by using the observations in the first group and the last three groups. The software reserves the observations in the second group for validation.The software proceeds in a similar manner for the third, fourth, and fifth models.
If you validate by using kfoldPredict, the software computes
predictions for the observations in group i by using the
ith model. In short, the software estimates a response for every
observation by using the model trained without that observation.
Creation
You can create a ClassificationPartitionedGAM model in two ways:
Create a cross-validated model from a GAM object
ClassificationGAMby using thecrossvalobject function.Create a cross-validated model by using the
fitcgamfunction and specifying one of the name-value arguments'CrossVal','CVPartition','Holdout','KFold', or'Leaveout'.
Properties
Object Functions
kfoldPredict | Classify observations in cross-validated classification model |
kfoldLoss | Classification loss for cross-validated classification model |
kfoldMargin | Classification margins for cross-validated classification model |
kfoldEdge | Classification edge for cross-validated classification model |
kfoldfun | Cross-validate function for classification |
Examples
Train a cross-validated GAM with 10 folds, which is the default cross-validation option, by using fitcgam. Then, use kfoldPredict to predict class labels for validation-fold observations using a model trained on training-fold observations.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereCreate a cross-validated GAM by using the default cross-validation option. Specify the 'CrossVal' name-value argument as 'on'.
rng('default') % For reproducibility CVMdl = fitcgam(X,Y,'CrossVal','on')
CVMdl =
ClassificationPartitionedGAM
CrossValidatedModel: 'GAM'
PredictorNames: {'x1' 'x2' 'x3' 'x4' 'x5' 'x6' 'x7' 'x8' 'x9' 'x10' 'x11' 'x12' 'x13' 'x14' 'x15' 'x16' 'x17' 'x18' 'x19' 'x20' 'x21' 'x22' 'x23' 'x24' 'x25' 'x26' 'x27' 'x28' 'x29' 'x30' 'x31' 'x32' 'x33' 'x34'}
ResponseName: 'Y'
NumObservations: 351
KFold: 10
Partition: [1×1 cvpartition]
NumTrainedPerFold: [1×1 struct]
ClassNames: {'b' 'g'}
ScoreTransform: 'logit'
Properties, Methods
The fitcgam function creates a ClassificationPartitionedGAM model object CVMdl with 10 folds. During cross-validation, the software completes these steps:
Randomly partition the data into 10 sets.
For each set, reserve the set as validation data, and train the model using the other 9 sets.
Store the 10 compact, trained models in a 10-by-1 cell vector in the
Trainedproperty of the cross-validated model objectClassificationPartitionedGAM.
You can override the default cross-validation setting by using the 'CVPartition', 'Holdout', 'KFold', or 'Leaveout' name-value argument.
Classify the observations in X by using kfoldPredict. The function predicts class labels for every observation using the model trained without that observation.
label = kfoldPredict(CVMdl);
Create a confusion matrix to compare the true classes of the observations to their predicted labels.
C = confusionchart(Y,label);

Compute the classification error.
L = kfoldLoss(CVMdl)
L = 0.0712
The average misclassification rate over 10 folds is about 7%.
Train a GAM by using fitcgam, and create a cross-validated GAM by using crossval and the holdout option. Then, use kfoldPredict to predict responses for validation-fold observations using a model trained on training-fold observations.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year. The classification task is to fit a model that predicts the salary category of people given their age, working class, education level, marital status, race, and so on.
load census1994census1994 contains the training data set adultdata and the test data set adulttest. To reduce the running time for this example, subsample 500 training observations from adultdata by using the datasample function.
rng('default') NumSamples = 5e2; adultdata = datasample(adultdata,NumSamples,'Replace',false);
Train a GAM that contains both linear and interaction terms for predictors. Specify to include all available interaction terms whose p-values are not greater than 0.05.
Mdl = fitcgam(adultdata,'salary','Interactions','all','MaxPValue',0.05);
Mdl is a ClassificationGAM model object.
Cross-validate the model by specifying a 30% holdout sample.
CVMdl = crossval(Mdl,'Holdout',0.3)CVMdl =
ClassificationPartitionedGAM
CrossValidatedModel: 'GAM'
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ResponseName: 'salary'
NumObservations: 500
KFold: 1
Partition: [1×1 cvpartition]
NumTrainedPerFold: [1×1 struct]
ClassNames: [<=50K >50K]
ScoreTransform: 'logit'
Properties, Methods
The crossval function creates a ClassificationPartitionedGAM model object CVMdl with the holdout option. During cross-validation, the software completes these steps:
Randomly select and reserve 30% of the data as validation data, and train the model using the rest of the data.
Store the compact, trained model in the
Trainedproperty of the cross-validated model objectClassificationPartitionedGAM.
You can choose a different cross-validation setting by using the 'CrossVal', 'CVPartition', 'KFold', or 'Leaveout' name-value argument.
Classify the validation-fold observations by using kfoldPredict. The function predicts class labels for the validation-fold observations by using the model trained on the training-fold observations. The function assigns the most frequently predicted label to the training-fold observations.
[labels,scores] = kfoldPredict(CVMdl);
Find the validation-fold observations. kfoldPredict returns 0 scores for both classes for the training-fold observations. Therefore, you can identify the validation-fold observations by finding the observations whose scores are all zeros.
idx = find(sum(abs(scores),2)~=0);
Create a confusion matrix to compare the true classes of the observations to their predicted labels, and compute the classification error for the validation-fold observations.
C = confusionchart(adultdata.salary(idx),labels(idx));
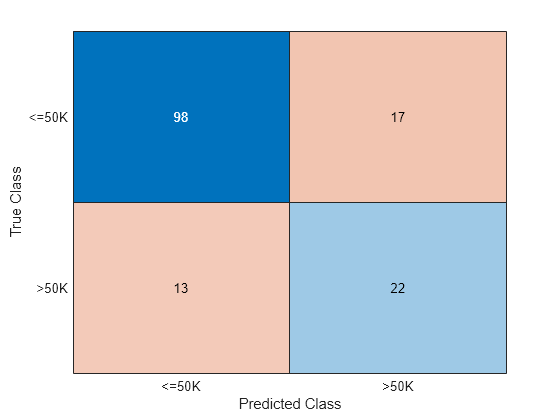
L = kfoldLoss(CVMdl)
L = 0.2000
Train a cross-validated generalized additive model (GAM) with 10 folds. Then, use kfoldLoss to compute cumulative cross-validation classification errors (misclassification rate in decimal). Use the errors to determine the optimal number of trees per predictor (linear term for predictor) and the optimal number of trees per interaction term.
Alternatively, you can find optimal values of fitcgam name-value arguments by using the OptimizeHyperparameters name-value argument. For an example, see Optimize GAM Using OptimizeHyperparameters.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionosphereCreate a cross-validated GAM by using the default cross-validation option. Specify the 'CrossVal' name-value argument as 'on'. Specify to include all available interaction terms whose p-values are not greater than 0.05.
rng('default') % For reproducibility CVMdl = fitcgam(X,Y,'CrossVal','on','Interactions','all','MaxPValue',0.05);
If you specify 'Mode' as 'cumulative' for kfoldLoss, then the function returns cumulative errors, which are the average errors across all folds obtained using the same number of trees for each fold. Display the number of trees for each fold.
CVMdl.NumTrainedPerFold
ans = struct with fields:
PredictorTrees: [65 64 59 61 60 66 65 62 64 61]
InteractionTrees: [1 2 2 2 2 1 2 2 2 2]
kfoldLoss can compute cumulative errors using up to 59 predictor trees and one interaction tree.
Plot the cumulative, 10-fold cross-validated, classification error (misclassification rate in decimal). Specify 'IncludeInteractions' as false to exclude interaction terms from the computation.
L_noInteractions = kfoldLoss(CVMdl,'Mode','cumulative','IncludeInteractions',false); figure plot(0:min(CVMdl.NumTrainedPerFold.PredictorTrees),L_noInteractions)

The first element of L_noInteractions is the average error over all folds obtained using only the intercept (constant) term. The (J+1)th element of L_noInteractions is the average error obtained using the intercept term and the first J predictor trees per linear term. Plotting the cumulative loss allows you to monitor how the error changes as the number of predictor trees in GAM increases.
Find the minimum error and the number of predictor trees used to achieve the minimum error.
[M,I] = min(L_noInteractions)
M = 0.0655
I = 23
The GAM achieves the minimum error when it includes 22 predictor trees.
Compute the cumulative classification error using both linear terms and interaction terms.
L = kfoldLoss(CVMdl,'Mode','cumulative')
L = 2×1
0.0712
0.0712
The first element of L is the average error over all folds obtained using the intercept (constant) term and all predictor trees per linear term. The second element of L is the average error obtained using the intercept term, all predictor trees per linear term, and one interaction tree per interaction term. The error does not decrease when interaction terms are added.
If you are satisfied with the error when the number of predictor trees is 22, you can create a predictive model by training the univariate GAM again and specifying 'NumTreesPerPredictor',22 without cross-validation.
Version History
Introduced in R2021a