incrementalLearner
Description
IncrementalMdl = incrementalLearner(Mdl)IncrementalMdl for anomaly detection, initialized using the
parameters provided in the one-class SVM model Mdl. Because its
property values reflect the knowledge gained from Mdl,
IncrementalMdl can detect anomalies given new observations, and it is
warm, meaning that the incremental fit function can
return scores and detect anomalies.
IncrementalMdl = incrementalLearner(Mdl,Name=Value)IncrementalMdl is
prepared for incremental learning before fit updates the
score threshold for anomaly detection. For example,
Solver="sgd",EstimationPeriod=500 specifies to use the stochastic
gradient descent solver, and to process 500 observations to estimate model hyperparameters
prior to training.
Examples
Train a one-class SVM model by using ocsvm, convert it to an incremental learner model, fit the incremental model to streaming data, and detect anomalies. Transfer training options from traditional to incremental learning.
Load Data
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau.
load census1994.matThe fit function of incrementalOneClassSVM does not support categorical predictors and does not use observations with missing values. Remove missing values in the data to reduce memory consumption and speed up training.
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
Remove the categorical predictors from the data.
Xtrain = removevars(adultdata,["workClass","education","marital_status", ... "occupation","relationship","race","sex","native_country","salary"]); Xstream = removevars(adulttest,["workClass","education","marital_status", ... "occupation","relationship","race","sex","native_country","salary"]);
Train One-Class SVM Model
Fit a one-class SVM model to the training data. Specify a random stream for reproducibility, and an anomaly contamination fraction of 0.001. Set KernelScale to "auto" so that the software selects an appropriate kernel scale parameter using a heuristic procedure.
rng(0,"twister"); % For reproducibility TTMdl = ocsvm(Xtrain, KernelScale="auto",ContaminationFraction=0.001, ... RandomStream=RandStream("mlfg6331_64"))
TTMdl =
OneClassSVM
CategoricalPredictors: []
ContaminationFraction: 1.0000e-03
ScoreThreshold: -0.0678
PredictorNames: {'age' 'fnlwgt' 'education_num' 'capital_gain' 'capital_loss' 'hours_per_week'}
KernelScale: 9.3699e+04
Lambda: 0.1632
Properties, Methods
TTMdl is a OneClassSVM model object representing a traditionally trained one-class SVM model.
Convert Trained Model
Convert the traditionally trained one-class SVM model to a one-class SVM model for incremental learning.
IncrementalMdl = incrementalLearner(TTMdl);
IncrementalMdl is an incrementalOneClassSVM model object that is ready for incremental learning and anomaly detection.
Fit Incremental Model and Detect Anomalies
Perform incremental learning on the Xstream data by using the fit function. To simulate a data stream, fit the model in chunks of 100 observations at a time. At each iteration:
Process 100 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store
medianscore, the median score value of the data chunk, to see how it evolves during incremental learning.Store
threshold, the score threshold value for anomalies, to see how it evolves during incremental learning.Store
numAnom, the number of detected anomalies in the chunk, to see how it evolves during incremental learning.
n = numel(Xstream(:,1)); numObsPerChunk = 100; nchunk = floor(n/numObsPerChunk); medianscore = zeros(nchunk,1); threshold = zeros(nchunk,1); numAnom = zeros(nchunk,1); % Incremental fitting rng("default"); % For reproducibility for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; [IncrementalMdl,tf,scores] = fit(IncrementalMdl,Xstream(idx,:)); medianscore(j) = median(scores); numAnom(j) = sum(tf); threshold(j) = IncrementalMdl.ScoreThreshold; end
Analyze Incremental Model During Training
To see how the median score, score threshold, and number of detected anomalies per chunk evolve during training, plot them on separate tiles.
tiledlayout(3,1); nexttile plot(medianscore) ylabel("Median Score") xlabel("Iteration") xlim([0 nchunk]) nexttile plot(threshold) ylabel("Score Threshold") xlabel("Iteration") xlim([0 nchunk]) nexttile plot(numAnom,"+") ylabel("Number of Anomalies") xlabel("Iteration") xlim([0 nchunk]) ylim([0 max(numAnom)+0.2])

totalAnomalies=sum(numAnom)
totalAnomalies = 16
anomfrac= totalAnomalies/n
anomfrac = 0.0011
The median score remains relatively constant at 26 for the first 58 iterations, after which it begins to rise. After 9 iterations, the score threshold begins to steadily drop from its initial value of 0. The software detects 16 anomalies in the Xstream data, yielding a total contamination fraction of 0.0011. You can suppress the output of scores and anomalies returned by fit during the initial iterations of incremental learning, when the model is still approaching a steady state, by specifying ScoreWarmupPeriod > 0 when you create IncrementalMdl using incrementalLearner.
Train a one-class SVM model by using ocsvm, and convert it to an incremental learner model that uses the stochastic gradient descent solver. Fit the incremental learner model to streaming data, and detect anomalies. Transfer training options from traditional to incremental learning.
Load Data
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau.
load census1994.matThe fit function of incrementalOneClassSVM does not support categorical predictors and does not use observations with missing values. Remove missing values in the data to reduce memory consumption and speed up training.
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
Remove the categorical predictors.
Xtrain = removevars(adultdata,["workClass","education","marital_status", ... "occupation","relationship","race","sex","native_country","salary"]); Xstream = removevars(adulttest,["workClass","education","marital_status", ... "occupation","relationship","race","sex","native_country","salary"]);
Train One-Class SVM Model
Fit a one-class SVM model to the training data. Specify a random stream for reproducibility, and an anomaly contamination fraction of 0.001. Set KernelScale to "auto" so that the software selects an appropriate kernel scale parameter using a heuristic procedure.
rng(0,"twister"); % For reproducibility TTMdl = ocsvm(Xtrain,ContaminationFraction=0.001, ... KernelScale="auto",RandomStream=RandStream("mlfg6331_64"), ... StandardizeData=true)
TTMdl =
OneClassSVM
CategoricalPredictors: []
ContaminationFraction: 1.0000e-03
ScoreThreshold: 0.1013
PredictorNames: {'age' 'fnlwgt' 'education_num' 'capital_gain' 'capital_loss' 'hours_per_week'}
KernelScale: 2.6954
Lambda: 0.1600
Properties, Methods
TTMdl is a OneClassSVM model object representing a traditionally trained one-class SVM model.
Convert Trained Model
Convert the traditionally trained one-class SVM model to a one-class SVM model for incremental learning. Specify the standard SGD solver and an estimation period of 5000 observations (the default is 1000 when a learning rate is required).
IncrementalMdl = incrementalLearner(TTMdl,Solver="sgd", ... EstimationPeriod=5000); details(IncrementalMdl)
incrementalOneClassSVM with properties:
KernelScale: 2.6954
Lambda: 0.1600
NumExpansionDimensions: 256
SolverOptions: [1×1 struct]
Solver: 'sgd'
FittedLoss: 'hinge'
Mu: [38.4379 1.8979e+05 10.1213 1.0920e+03 88.3725 40.9312]
Sigma: [13.1347 1.0565e+05 2.5500 7.4063e+03 404.2984 11.9800]
EstimationPeriod: 5000
IsWarm: 0
ContaminationFraction: 1.0000e-03
NumTrainingObservations: 0
NumPredictors: 6
ScoreThreshold: 0.1021
ScoreWarmupPeriod: 0
PredictorNames: {'age' 'fnlwgt' 'education_num' 'capital_gain' 'capital_loss' 'hours_per_week'}
ScoreWindowSize: 1000
Methods, Superclasses
IncrementalMdl is an incrementalOneClassSVM model object that is ready for incremental learning and anomaly detection.
Fit Incremental Model and Detect Anomalies
Perform incremental learning on the Xstream data by using the fit function. To simulate a data stream, fit the model in chunks of 100 observations at a time. At each iteration:
Process 100 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store
medianscore, the median score value of the data chunk, to see how it evolves during incremental learning.Store
threshold, the score threshold value for anomalies, to see how it evolves during incremental learning.Store
numAnom, the number of detected anomalies in the chunk, to see how it evolves during incremental learning.
n = numel(Xstream(:,1)); numObsPerChunk = 100; nchunk = floor(n/numObsPerChunk); medianscore = zeros(nchunk,1); threshold = zeros(nchunk,1); numAnom = zeros(nchunk,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; [IncrementalMdl,tf,scores] = fit(IncrementalMdl,Xstream(idx,:)); medianscore(j) = median(scores); numAnom(j) = sum(tf); threshold(j) = IncrementalMdl.ScoreThreshold; end
Analyze Incremental Model During Training
To see how the median score, score threshold, and number of detected anomalies per chunk evolve during training, plot them on separate tiles.
tiledlayout(3,1); nexttile plot(medianscore) ylabel("Median Score") xlabel("Iteration") xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"r-.") xlim([0 nchunk]) nexttile plot(threshold) ylabel("Score Threshold") xlabel("Iteration") xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"r-.") xlim([0 nchunk]) nexttile plot(numAnom,"+") ylabel("Anomalies") xlabel("Iteration") xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"r-.") xlim([0 nchunk]) ylim([0 max(numAnom)+0.2])
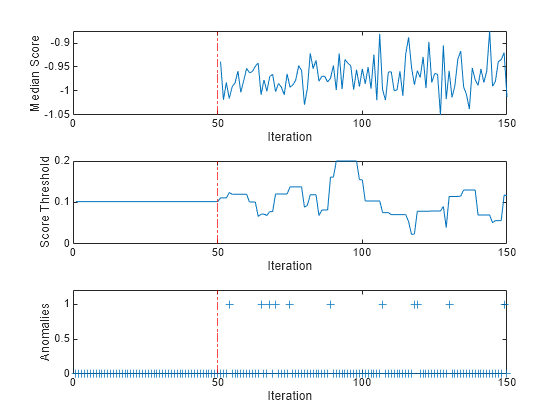
totalanomalies=sum(numAnom)
totalanomalies = 11
anomfrac= totalanomalies/(n-IncrementalMdl.EstimationPeriod)
anomfrac = 0.0011
During the estimation period, fit estimates the learning rate using the observations, and does not fit the model or update the score threshold. After the estimation period, fit updates the model and returns the observation scores and the indices of observations with scores above the score threshold value as anomalies. A negative score value with large magnitude indicates a normal observation, and a large positive value indicates an anomaly. The median score fluctuates between approximately 1 and 0.9. The score threshold fluctuates between 0.02 and 0.2. The software detects 11 anomalies in the Xstream data after the estimation period, yielding a total contamination fraction of 0.0011.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
Version History
Introduced in R2023b