Main Content
Results for
Seeing a colleague make this mistake (one I've had to fix multiple times in other's work too) makes me want to ask the community: would you like the awgn() function/blocks to give the option for creating a SNR at the bandwidth of the signal? Your typical flow is something like this:
- Create a signal, usually at some nominal upsampling factor (e.g., 4) such that it's now nicely over sampled, especially if you're using a RRC or similar pulse shaping filter.
- Potentially add a frequency offset (which might make the sample frequency even higher)
- Add AWGN channel model for a desired SNR
- Put this into your detector/receiver model
The problem is, when someone says, "I'm detecting XYZ at foo SNR," it should not magically improve as a function of the oversample. The problem isn't that awgn() generates white noise, that's what it's supposed to do and the typical receiver has noise across the entire band. The problem is that SNR is most properly defined as the signal power over the noise power spectral density times the signal's noise equivalent bandwidth. Now I looked and there's no handy function for computing NEBW for an input signal (there's just a function for assessing analysis windows). In practice it can get a bit tricky. The occupied bandwidth or HPBW are often close enough to the NEBW, we're usually not haggling over hundredths of a dB. So, in my not so humble opinion, the "measured" flag for awgn() should give an option for bandwidth matching or at least document the behavior better in the help page. All too often I'm seeing 3-6 (or worse) dB errors because people aren't taking the signal's bandwidth into account.
good afternoon everyone my name is Dundu lawan haruna ,i'm a final year student at the department of computer engineering ABU Zaria, Nigerian , and i wanted to do my final year project based on computer vision : project topic , designing an eye glasses to help those people with visual imparement to be able to navigate enviroment efficiently , that's why i need a support from you guys ,all advised are highly well come , thank you for your support.
You are invited to join our 2023 community contest – MATLAB Flipbook Mini Hack! This year’s contest revolves around creating interesting animations using MATLAB.
Whether you are a seasoned MATLAB user or just getting started, this contest offers a fantastic opportunity to showcase your skills, learn from others, and engage with the vibrant MATLAB Central community.
Timeframe
This contest runs for 4 weeks from Nov. 6th to Dec. 3rd.
How to play
- Create a new animation or remix an existing one with up to 2,000 characters of code.
- Simply vote on the animations you love!
Prizes
You will have opportunities to win compelling prizes, including Amazon gift cards, MathWorks T-shirts, and virtual badges. We will give out both weekly prizes and grand prizes.


The MATLAB Central Community team


I rarely/never save .fig files
47%
Continue working on it later
16%
Archive for future reference
23%
Share within my organization
10%
Share outside my organization
2%
Other (please leave a comment)
2%
2097 votes
I know the latest version of MATLAB R2023b has this feature already, put it should be added to R2023a as well because of its simplicity and convenience.
Basically, I want to make a bar graph that lets me name each column in a basic bar graph:
y=[100 99 100 200 200 300 500 800 1000];
x=["0-4" "5-17" "18-29" "30-39" "40-49" "50-64" "65-74" "75-84" "85+"];
bar(x,y)
However, in R2023a, this isn't a feature. I think it should be added because it helps to present data and ideas more clearly and professionally, which is the purpose of a graph to begin with.
Recently, I came across a post about the JIT compiler on this Korean blog. In the post. The writer discussed the concept of the "Compile Threshold" and how it is calculated.
"The JVM accumulates the number of calls for each method called and compiles when the number exceeds a certain number. In other words, there is a standard for checking how often it is called and then deciding, 'It is time to compile.' This standard is called the compilation threshold. But what is this and why should it be used as a standard?"
The concept of the "Compile Threshold," as used above, seems to be more commonly associated with Tracing just-in-time compilation.
The writer used the simple Java code below to calculate the threshold.
for (int i = 0; i < 500; ++i) {
long startTime = System.nanoTime();
for (int j = 0; j < 1000; ++j) {
new Object();
}
long endTime = System.nanoTime();
System.out.printf("%d\t%d\n", i, endTime - startTime);
}
Since the MATLAB execution engine uses JIT compilation, I just wanted to perform the same experiment that the writer did.
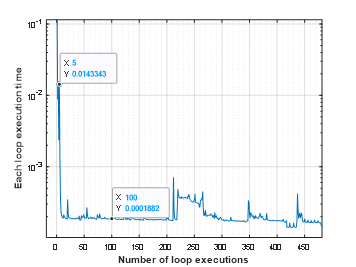
I experimented using simple codes based on the code in the blog. I iterated a function 500 time using for-loop and calculated the execution time for each iteration using tic and toc. Then I plotted the execution time for each loop as blow. First five execution times are much higher than followings (10 times!) The test is very rough so I am not sure that I can conclude "MATLAB has Compile Threshold and it is 5!" but this value is actually correct ;-)
t0 = 0;
tfinal = 10;
y0 = [20;20];
timeToRun = zeros(500,1);
for i = 1:500
tStart = tic;
[preypeaks,predatorpeaks] = solvelotka(t0, tfinal, y0);
tEnd = toc(tStart);
timeToRun(i) = tEnd;
end
VS Code Extension for MATLAB was introduced back in April and has been downloaded 75K times since. Do people here use VS Code for writing MATLAB code?
Would it be a good thing to have implicit expansion enabled for cat(), horzcat(), vertcat()? There are often situations where I would like to be able to do things like this:
x=[10;20;30;40];
y=[11;12;13;14];
z=cat(3, 0,1,2);
C=[x,y,z]
with the result,
C(:,:,1) =
10 11 0
20 12 0
30 13 0
40 14 0
C(:,:,2) =
10 11 1
20 12 1
30 13 1
40 14 1
C(:,:,3) =
10 11 2
20 12 2
30 13 2
40 14 2











Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom(English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)