mfcc
Extract MFCC, log energy, delta, and delta-delta of audio signal
Syntax
Description
coeffs = mfcc(___,Name=Value)
Example: coeffs = mfcc(audioIn,fs,LogEnergy="replace") returns
mel-frequency cepstral coefficients for the audio input signal sampled at
fs Hz. The first coefficient in the coeffs
vector is replaced with the log energy value.
[
also returns the delta, delta-delta, and location of samples corresponding to each
window of data. You can specify an input combination from any of the previous
syntaxes.coeffs,delta,deltaDelta,loc] = mfcc(___)
mfcc(___) with no output arguments plots the
mel-frequency cepstral coefficients. Before plotting, the coefficients are
normalized to have mean 0 and standard deviation 1.
If the input is in the time domain, the coefficients are plotted against time.
If the input is in the frequency domain, the coefficients are plotted against frame number.
If the log energy is extracted, then it is also plotted.
Examples
Compute the mel frequency cepstral coefficients of a speech signal using the mfcc function. The function returns delta, the change in coefficients, and deltaDelta, the change in delta values. The log energy value that the function computes can prepend the coefficients vector or replace the first element of the coefficients vector. This is done based on whether you set the LogEnergy argument to "append" or "replace".
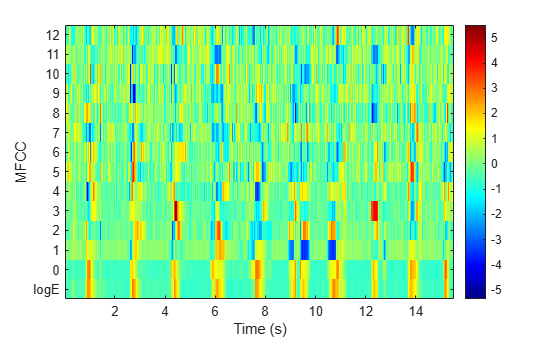
Read an audio signal from the Counting-16-44p1-mono-15secs.wav file using the audioread function. The mfcc function processes the entire speech data in a batch. Based on the number of input rows, the window length, and the overlap length, mfcc partitions the speech into 1551 frames and computes the cepstral features for each frame. Each row in the coeffs matrix corresponds to the log-energy value followed by the 13 mel-frequency cepstral coefficients for the corresponding frame of the speech file. The function also computes loc, the location of the last sample in each input frame.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav");
[coeffs,delta,deltaDelta,loc] = mfcc(audioIn,fs);Plot the normalized coefficients.
mfcc(audioIn,fs)
Read in an audio file and convert it to a frequency representation.
[audioIn,fs] = audioread("Rainbow-16-8-mono-114secs.wav"); win = hann(1024,"periodic"); S = stft(audioIn,"Window",win,"OverlapLength",512,"Centered",false);
To extract the mel-frequency cepstral coefficients, call mfcc with the frequency-domain audio. Ignore the log-energy.
coeffs = mfcc(S,fs,"LogEnergy","Ignore");
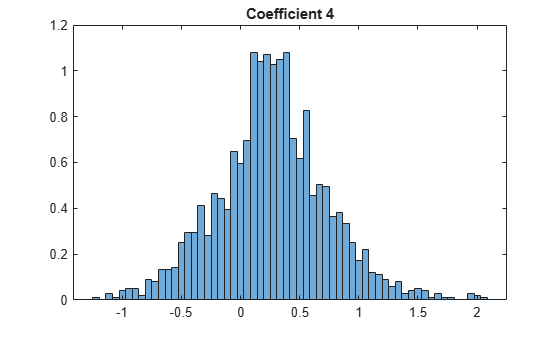
In many applications, MFCC observations are converted to summary statistics for use in classification tasks. Plot a probability density function for one of the mel-frequency cepstral coefficients to observe its distributions.
nbins = 60; coefficientToAnalyze =4; histogram(coeffs(:,coefficientToAnalyze+1),nbins,"Normalization","pdf") title(sprintf("Coefficient %d",coefficientToAnalyze))
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
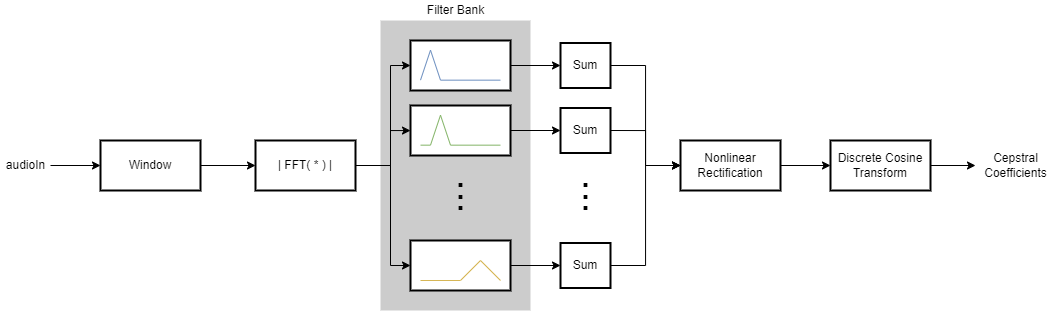
Mel-frequency cepstrum coefficients are popular features extracted from speech signals for use in recognition tasks. In the source-filter model of speech, cepstral coefficients are understood to represent the filter (vocal tract). The vocal tract frequency response is relatively smooth, whereas the source of voiced speech can be modeled as an impulse train. As a result, the vocal tract can be estimated by the spectral envelope of a speech segment.
The motivating idea of mel-frequency cepstral coefficients is to compress information about the vocal tract (smoothed spectrum) into a small number of coefficients based on an understanding of the cochlea. Although there is no hard standard for calculating the coefficients, the basic steps are outlined by the diagram.
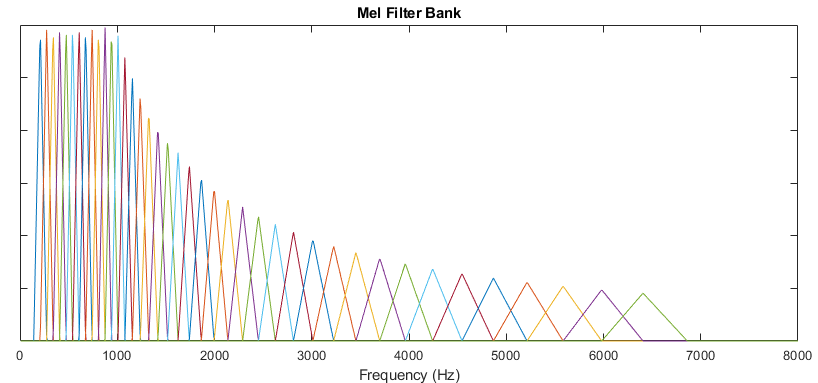
The default mel filter bank linearly spaces the first 10 triangular filters and logarithmically spaces the remaining filters.
References
[1] Rabiner, Lawrence R., and Ronald W. Schafer. Theory and Applications of Digital Speech Processing. Upper Saddle River, NJ: Pearson, 2010.
[2] Auditory Toolbox. https://engineering.purdue.edu/~malcolm/interval/1998-010/AuditoryToolboxTechReport.pdf