separateSpeakers
Syntax
Description
y = separateSpeakers(audioIn,fs,Name=Value)separateSpeakers(audioIn,fs,NumSpeakers=3) separates a speech signal
that is known to contain three speakers.
[
also returns the residual signal after performing iterative speaker separation. Use this
syntax in combination with any of the input arguments in previous syntaxes. This syntax does
not apply if y,r] = separateSpeakers(___)NumSpeakers is 2 or
3.
separateSpeakers(___) with no output arguments plots
the input signal and the separated speaker signals. This function also plots the residual
signal if NumSpeakers is unspecified or set to
1.
Examples
Try calling separateSpeakers in the command line. If the required model files are not installed, then the function throws an error and provides a link to download them. Click the link, and unzip the file to a location on the MATLAB® path.
Alternatively, execute the following commands to download and unzip the separateSpeakers model files to your temporary directory.
downloadFolder = fullfile(tempdir,"separateSpeakerDownload"); loc = websave(downloadFolder,"https://ssd.mathworks.com/supportfiles/audio/separateSpeakers.zip"); modelsLocation = tempdir; unzip(loc,modelsLocation) addpath(fullfile(modelsLocation,"separateSpeakers"))
Create an audio signal that combines the speech of two speakers. Listen to the mixed signal.
[s,fs] = audioread("MultipleSpeakers-16-8-4channel-5secs.flac");
s = sum(s(:,1:2),2);
x = s./max(abs(s));
sound(x,fs)Call separateSpeakers to separate the individual speakers from the signal. By default, separateSpeakers estimates how many speakers to separate from the input. Inspect the output dimensions to see how many speakers the function separates. In this case, separateSpeakers correctly detects two different speakers.
y = separateSpeakers(x,fs); size(y)
ans = 1×2
40000 2
Listen to the first separated speaker.
sound(y(:,1),fs)
Listen to the second separated speaker.
sound(y(:,2),fs)
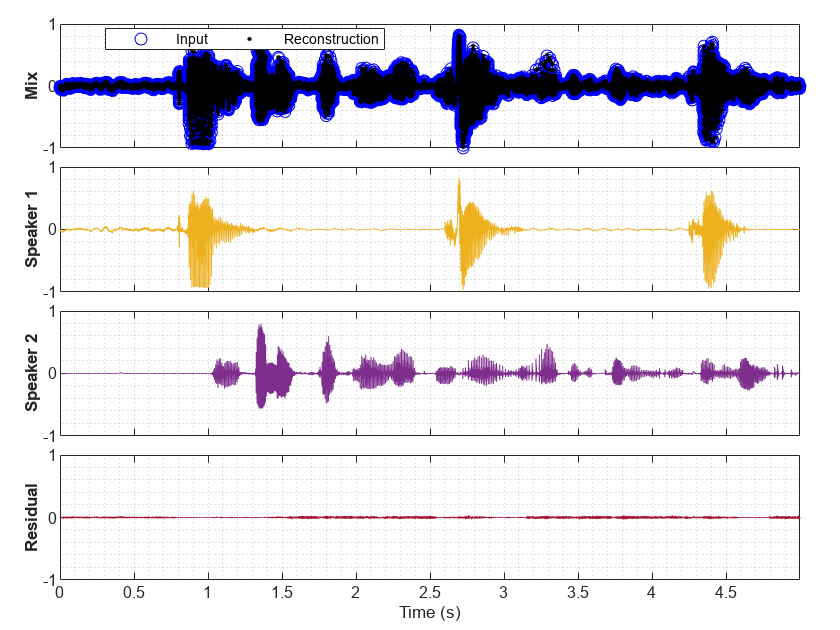
Call separateSpeakers with no output arguments to plot the input signal, the separated signals, the residual, and the reconstructed input.
separateSpeakers(x,fs)
Create an audio signal that combines the speech of three speakers with different scaling factors. Listen to the mixed signal.
[s,fs] = audioread("MultipleSpeakers-16-8-4channel-5secs.flac");
x = sum(s(:,1:3).*[1,0.5,0.1],2);
x = x./max(abs(x));
sound(x,fs)Call separateSpeakers with NumSpeakers set to 3 to separate the three known speakers from the signal.
y = separateSpeakers(x,fs,NumSpeakers=3);
Listen to the first separated speaker.
sound(y(:,1),fs)
Listen to the second separated speaker.
sound(y(:,2),fs)
Listen to the third separated speaker.
sound(y(:,3),fs)
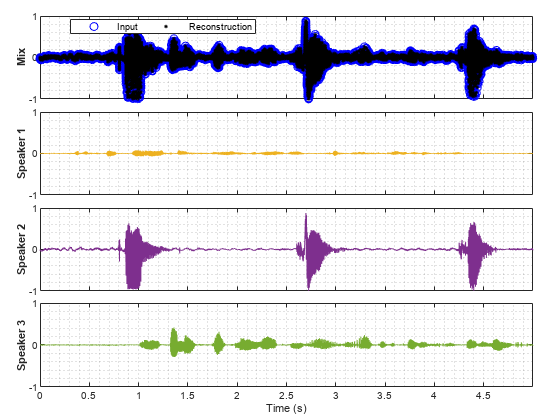
Call separateSpeakers with no output arguments to plot the input signal, the separated signals, the residual, and the reconstructed input.
separateSpeakers(x,fs,NumSpeakers=3)
If you do not specify NumSpeakers, or if you specify NumSpeakers as 1, separateSpeakers also returns the residual signal. The residual is the part of the original signal that is "left over" after separating out the speaker or speakers.
Create an audio signal that combines the speech of two speakers. Listen to the mixed signal.
[s,fs] = audioread("MultipleSpeakers-16-8-4channel-5secs.flac");
s = sum(s(:,1:2),2);
x = s./max(abs(s));
sound(x,fs)Call separateSpeakers with NumSpeakers set to 1 to separate a single speaker signal from the input. Specify an additional output argument r to obtain the residual. Listen to the separated speaker.
[y,r] = separateSpeakers(x,fs,NumSpeakers=1); sound(y,fs)
Listen to the residual signal.
sound(r,fs)
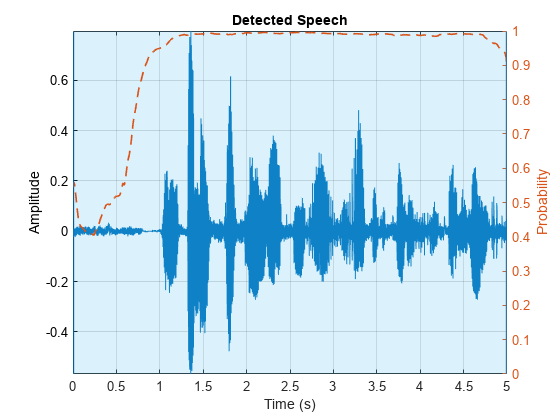
Call detectspeechnn with no output arguments to plot the detected speech in the residual.
detectspeechnn(r,fs)
Create an audio signal that combines the speech of two speakers. Listen to the mixed signal.
[s,fs] = audioread("MultipleSpeakers-16-8-4channel-5secs.flac");
s = sum(s(:,1:2),2);
x = s./max(abs(s));
sound(x,fs)Call separateSpeakers with ConserveEnergy set to false to simply scale the output signals to have a maximum absolute value of 1. Call the function with no output arguments to plot the signals.
separateSpeakers(x,fs,ConserveEnergy=false)

Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The separateSpeakers function uses a pretrained deep learning model
to separate the individual speaker signals. The model that it uses depends on the
NumSpeakers argument.
If you do not specify
NumSpeakers,separateSpeakersuses a Conv-TasNet [1] model with "one-and-rest" iterative speaker separation [4].If you set
NumSpeakersto1,separateSpeakersuses a Conv-TasNet model with one iteration of one-and-rest separation.If you set
NumSpeakersto2,separateSpeakersuses a SepFormer [3] model trained to output two speaker signals. This neural network uses pretrained weights from thesepformer-libri2mixmodel provided by SpeechBrain [2].If you set
NumSpeakersto3,separateSpeakersuses a SepFormer model trained to output three speaker signals. This neural network uses pretrained weights from thesepformer-libri3mixmodel provided by SpeechBrain [2].
The separateSpeakers function can separate speech from a signal
with an unknown number of speakers using a model that is trained to perform one-and-rest
speech separation. In one-and-rest speech separation, the model takes a mixed speech signal
and returns two signals: the speech of one individual speaker and the "rest" of the signal,
which is the residual of the original signal after separating out the one speaker.
The function uses one-and-rest speech separation iteratively. First, it separates the mixed speech signal into one speaker and the residual. Then, it uses voice activity detection (VAD) to determine if the residual contains more speakers. If it does not detect speech in the residual, the function stops and returns the separated speakers. Otherwise, it repeats the process and performs one-and-rest speech separation on the residual signal.

References
[1] Luo, Yi, and Nima Mesgarani. “Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation.” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, Aug. 2019, pp. 1256–66. DOI.org (Crossref), https://doi.org/10.1109/TASLP.2019.2915167.
[2] Ravanelli, Mirco, et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv, 8 June 2021. arXiv.org, http://arxiv.org/abs/2106.04624
[3] Subakan, Cem, et al. “Attention Is All You Need In Speech Separation.” ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2021, pp. 21–25. DOI.org (Crossref), https://doi.org/10.1109/ICASSP39728.2021.9413901.
[4] Takahashi, Naoya, et al. “Recursive Speech Separation for Unknown Number of Speakers.” Interspeech 2019, ISCA, 2019, pp. 1348–52. DOI.org (Crossref), https://doi.org/10.21437/Interspeech.2019-1550.
Extended Capabilities
Version History
Introduced in R2023b