stretchAudio
Time-stretch audio
Description
Examples
Read in an audio signal. Listen to the audio signal and plot it over time.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav"); t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on
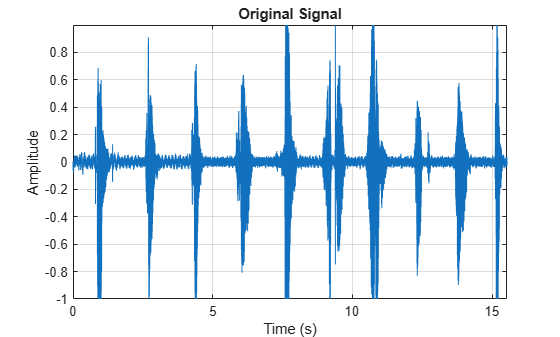
sound(audioIn,fs)
Use stretchAudio to apply a 1.5 speedup factor. Listen to the modified audio signal and plot it over time. The sample rate remains the same, but the duration of the signal has decreased.
audioOut = stretchAudio(audioIn,1.5); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 1.5') axis tight grid on
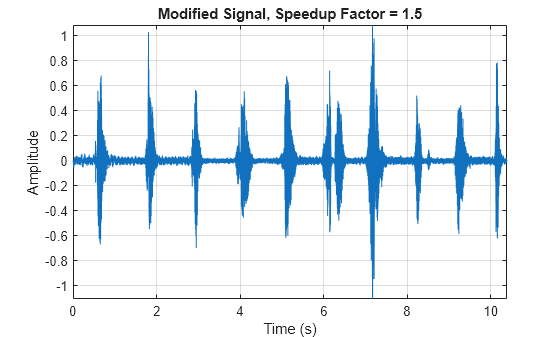
sound(audioOut,fs)
Slow down the original audio signal by a 0.75 factor. Listen to the modified audio signal and plot it over time. The sample rate remains the same as the original audio, but the duration of the signal has increased.
audioOut = stretchAudio(audioIn,0.75); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 0.75') axis tight grid on
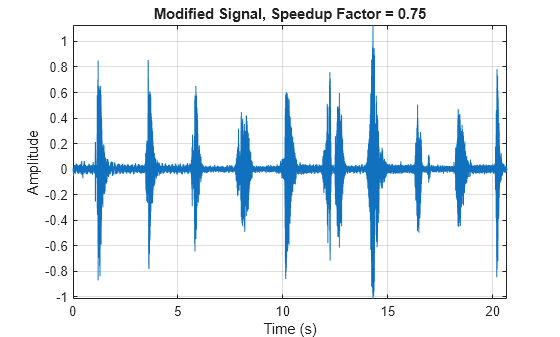
sound(audioOut,fs)
stretchAudio supports TSM on frequency-domain audio when using the default vocoder method. Applying TSM to frequency-domain audio enables you to reuse your STFT computation for multiple TSM factors.
Read in an audio signal. Listen to the audio signal and plot it over time.
[audioIn,fs] = audioread('FemaleSpeech-16-8-mono-3secs.wav'); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Convert the audio signal to the frequency domain.
win = sqrt(hann(256,'periodic')); ovrlp = 192; S = stft(audioIn,'Window',win,'OverlapLength',ovrlp,'Centered',false);
Speed up the audio signal by a factor of 1.4. Specify the window and overlap length used to create the frequency-domain representation.
alpha = 1.4; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 1.4') axis tight grid on

Slow down the audio signal by a factor of 0.8. Specify the window and overlap length used to create the frequency-domain representation.
alpha = 0.8; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 0.8') axis tight grid on

The default TSM method (vocoder) enables you to additionally apply phase-locking to increase the fidelity to the original audio.
Read in an audio signal. Listen to the audio signal and plot it over time.
[audioIn,fs] = audioread("SpeechDFT-16-8-mono-5secs.wav"); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Phase-locking adds a nontrivial computational load to TSM and is not always required. By default, phase-locking is disabled. Apply a speedup factor of 1.8 to the input audio signal. Listen to the audio signal and plot it over time.
alpha = 1.8; tic audioOut = stretchAudio(audioIn,alpha); processingTimeWithoutPhaseLocking = toc
processingTimeWithoutPhaseLocking = 0.0798
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = false') axis tight grid on

Apply the same 1.8 speedup factor to the input audio signal, this time enabling phase-locking. Listen to the audio signal and plot it over time.
tic
audioOut = stretchAudio(audioIn,alpha,"LockPhase",true);
processingTimeWithPhaseLocking = tocprocessingTimeWithPhaseLocking = 0.1154
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = true') axis tight grid on

The waveform similarity overlap-add (WSOLA) TSM method enables you to specify the maximum number of samples to search for the best signal alignment. By default, WSOLA delta is the number of samples in the analysis window minus the number of samples overlapped between adjacent analysis windows. Increasing the WSOLA delta increases the computational load but might also increase fidelity.
Read in an audio signal. Listen to the first 10 seconds of the audio signal.
[audioIn,fs] = audioread('RockGuitar-16-96-stereo-72secs.flac');
sound(audioIn(1:10*fs,:),fs)Apply a TSM factor of 0.75 to the input audio signal using the WSOLA method. Listen to the first 10 seconds of the resulting audio signal.
alpha = 0.75; tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola"); processingTimeWithDefaultWSOLADelta = toc
processingTimeWithDefaultWSOLADelta = 19.4403
sound(audioOut(1:10*fs,:),fs)
Apply a TSM factor of 0.75 to the input audio signal, this time increasing the WSOLA delta to 1024. Listen to the first 10 seconds of the resulting audio signal.
tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola","WSOLADelta",1024); processingTimeWithIncreasedWSOLADelta = toc
processingTimeWithIncreasedWSOLADelta = 25.5306
sound(audioOut(1:10*fs,:),fs)
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The phase vocoder algorithm is a frequency-domain approach to TSM [1][2]. The basic steps of the phase vocoder algorithm are:
The algorithm windows a time-domain signal at interval η, where
η = numel(. The windows are then converted to the frequency domain.Window) -OverlapLengthTo preserve horizontal (across time) phase coherence, the algorithm treats each bin as an independent sinusoid whose phase is computed by accumulating the estimates of its instantaneous frequency.
To preserve vertical (across an individual spectrum) phase coherence, the algorithm locks the phase advance of groups of bins to the phase advance of local peaks. This step only applies if
LockPhaseis set totrue.The algorithm returns the modified spectrogram to the time domain, with windows spaced at intervals of δ, where δ ≈ η/α. α is the speedup factor specified by the
alphainput argument.

The WSOLA algorithm is a time-domain approach to TSM [1][2]. WSOLA is an extension of
the overlap and add (OLA) algorithm. In the OLA algorithm, a time-domain signal is windowed
at interval η, where η = numel(. To construct the time-scale modified
output audio, the windows are spaced at interval δ, where δ ≈ η/α. α is the TSM factor
specified by the Window) -
OverlapLengthalpha input argument.

The OLA algorithm does a good job of recreating the magnitude spectra but can introduce
phase jumps between windows. The WSOLA algorithm attempts to smooth the phase jumps by
searching WSOLADelta samples around the η interval for a window that
minimizes phase jumps. The algorithm searches for the best window iteratively, so that each
successive window is chosen relative to the previously selected window.

If WSOLADelta is set to 0, then the algorithm
reduces to OLA.
References
[1] Driedger, Johnathan, and Meinard Müller. "A Review of Time-Scale Modification of Music Signals." Applied Sciences. Vol. 6, Issue 2, 2016.
[2] Driedger, Johnathan. "Time-Scale Modification Algorithms for Music Audio Signals", Master's thesis, Saarland University, Saarbrücken, Germany, 2011.
Extended Capabilities
Version History
Introduced in R2019b