egcitest
Engle-Granger cointegration test
Syntax
Description
h = egcitest(Y)egcitest forms test statistics by regressing the
response data Y(:,1) onto the predictor data
Y(:,2:end), and then it tests the residuals for a unit root.
StatTbl = egcitest(Tbl)
The response variable in the regression is the first table variable, and all other
variables are the predictor variables. To select a different response variable for the
regression, use the ResponseVariable name-value argument. To select
different predictor variables, use the PredictorNames name-value
argument.
[___] = egcitest(___,
specifies options using one or more name-value arguments in
addition to any of the input argument combinations in previous syntaxes.
Name=Value)egcitest returns the output argument combination for the
corresponding input arguments.
Some options control the number of tests to conduct. The following conditions apply when
egcitest conducts multiple tests:
For example, egcitest(Tbl,ResponseVariable="GDP",Alpha=0.025,Lags=[0
1]) chooses GDP as the response variable from the table
Tbl and conducts two tests at a level of significance of 0.025. The
first test includes 0 lag in the residual regression, and the second test
includes 1 lag in the residual regression.
[___,
additionally returns the following structures of regression statistics, which are required
to form the test statistic:reg1,reg2] = egcitest(___)
reg1– Statistics resulting from the cointegrating regression of the specified response variableResponseVariableonto the specified predictor variablesPredictorVariablesreg2– Statistics resulting from the residual regression implemented by the specified unit root testRReg
Examples
Test a multivariate time series for cointegration using the default values of the Engle-Granger cointegration test. Input the time series data as a numeric matrix.
Load data of Canadian inflation and interest rates Data_Canada.mat, which contains the series in the matrix Data.
load Data_Canada
series'ans = 5×1 cell
{'(INF_C) Inflation rate (CPI-based)' }
{'(INF_G) Inflation rate (GDP deflator-based)'}
{'(INT_S) Interest rate (short-term)' }
{'(INT_M) Interest rate (medium-term)' }
{'(INT_L) Interest rate (long-term)' }
Test the interest rate series for cointegration by using the Engle-Granger cointegration test. Use default options and return the rejection decision and -value.
h = egcitest(Data(:,3:end))
h = logical
0
egcitest uses the test by default, and it fails to reject the null hypothesis (h = 0) of no cointegration among the interest rate series.
Load data of Canadian inflation and interest rates Data_Canada.mat.
load Data_CanadaTest the interest rate series for cointegration by using the Engle-Granger cointegration test. Use default options and return the rejection decision, -value, -test statistic, and critical value.
[h,pValue,stat,cValue] = egcitest(Data(:,3:end))
h = logical
0
pValue = 0.0526
stat = -3.9321
cValue = -3.9563
Conduct the Engle-Granger cointegration test on a multivariate time series using default options, which use the first table variable as the response, all other table variables as predictors, and includes a constant term in the cointegrating regression. Return a table of test results.
Load data of Canadian inflation and interest rates Data_Canada.mat. Convert the table DataTable to a timetable.
load Data_Canada
dates = datetime(dates,12,31);
TT = table2timetable(DataTable,RowTimes=dates);
TT.Observations = [];Conduct the Engel-Granger cointegration test by passing the timetable to egcitest and using default options. For the cointegrating regression, egcitest uses the CPI-based inflation rate as the response variable and all other variables in the timetable as predictors.
StatTbl = egcitest(TT)
StatTbl=1×9 table
h pValue stat cValue Lags Alpha Test CReg RReg
_____ _________ _______ _______ ____ _____ ______ _____ _______
Test 1 true 0.0023851 -6.2491 -4.7673 0 0.05 {'t1'} {'c'} {'ADF'}
StatTbl is a table of test results. The rows correspond to variables in the input timetable TT, and the columns correspond to the rejection decision, and corresponding -value, decision statistics, and specified test options. In this case, the test rejects the null hypothesis in favor of the alternative of cointegration among all the table variables.
By default, egcitest includes all input table variables in the cointegration test. To select a response variable for the cointegrating regression, set the ResponseVariable option. To select predictor variables, set the PredictorVariables option.
Load data of Canadian inflation and interest rates Data_Canada.mat. Convert the table DataTable to a timetable of the interest rate series only.
load Data_Canada dates = datetime(dates,12,31); idxINT = contains(DataTable.Properties.VariableNames,"INT"); TT = table2timetable(DataTable(:,idxINT),RowTimes=dates); TT.Observations = [];
Plot the interest rate series.
figure plot(TT.Time,TT.Variables) legend(series(idxINT),Location="northwest") grid on
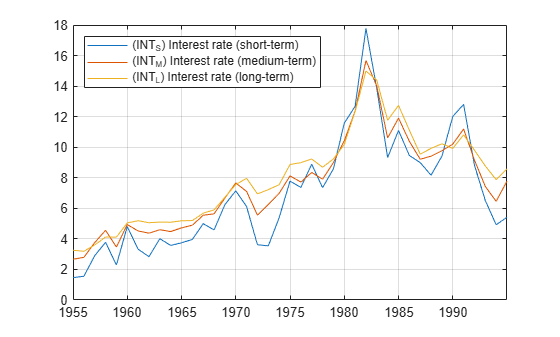
Reproduce row 1 of Table II in [3] by testing for cointegration, specifying the default variable assignments for the cointegrating regression and deterministic terms (response variable is INT_S, the other interest rates and are predictors, and the model has a constant ), and specifying the and tests. Return the cointegrating regression statistics.
[StatTbl,reg] = egcitest(TT,Test=["t1" "t2"]); StatTbl
StatTbl=2×9 table
h pValue stat cValue Lags Alpha Test CReg RReg
_____ ________ _______ _______ ____ _____ ______ _____ _______
Test 1 false 0.052627 -3.9321 -3.9563 0 0.05 {'t1'} {'c'} {'ADF'}
Test 2 true 0.020157 -25.454 -22.115 0 0.05 {'t2'} {'c'} {'ADF'}
The test (Test 1) fails to reject the null hypothesis, but the test (Test 2) rejects the null hypothesis in favor of the presence of cointegration.
Plot the estimated cointegrating relation using the regression statistics from the test , where .
c = reg(2).coeff(1);
b = reg(2).coeff(2:3);
figure
plot(TT.Time,TT.Variables*[1; -b] - c)
grid on
Input Arguments
Name-Value Arguments
Output Arguments
Tips
To draw valid inferences from the test, determine a suitable value for
Lags. For more details, see theadftestTips and thepptestTips.Samples with less than approximately 20 through 40 observations (depending on the dimension of the data
numDims) can yield unreliable critical values, and therefore unreliable inferences. See [3].If a test result suggests that the time series are cointegrated, you can use the residuals as data for the error-correction term in a VEC representation of the variables. Follow this procedure:
Alternative Functionality
App
The Econometric Modeler app enables you to conduct the Engle-Granger cointegration test.
References
[2] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
Version History
Introduced in R2011a