train
Train reinforcement learning agents within a specified environment
Syntax
Description
trainStats = train(env,agents)env, using default training options, and returns
training results in trainStats. Although
agents is an input argument, after each training
episode, train updates the parameters of each agent
specified in agents to maximize their expected long-term
reward from the environment. This is possible because each agent is a handle
object. When training terminates, agents reflects the state
of each agent at the end of the final training episode.
Note
To train an off-policy agent offline using existing data, use
trainFromData.
trainStats = train(agents,env)
trainStats = train(___,trainOpts)agents within env, using the
training options object trainOpts. Use training options to
specify training parameters such as the criteria for terminating training, when
to save agents, the maximum number of episodes to train, and the maximum number
of steps per episode.
trainStats = train(___,prevTrainStats)prevTrainStats, which is returned by
the previous function call to train.
trainStats = train(___,Name=Value)
Examples
Train the agent configured in the Train PG Agent with Custom Actor Network to Balance Discrete Cart-Pole example, within the corresponding environment. The observation from the environment is a vector containing the position and velocity of a cart, as well as the angular position and velocity of the pole. The action is a scalar with two possible elements (a force of either -10 or 10 Newtons applied to a cart).
Load the file containing the environment and a PG agent already configured for it.
load RLTrainExample.matSpecify some training parameters using rlTrainingOptions. These parameters include the maximum number of episodes to train, the maximum steps per episode, and the conditions for terminating training. For this example, use a maximum of 2000 episodes and 500 steps per episode. Instruct the training to stop when the average reward over the previous twenty episodes reaches 495. Create a default options object and use dot notation to change some of the parameter values.
trainOpts = rlTrainingOptions;
trainOpts.MaxEpisodes = 2000;
trainOpts.MaxStepsPerEpisode = 500;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 495;
trainOpts.ScoreAveragingWindowLength = 20;During training, the train command can save candidate agents that give good results. Further configure the training options to save an agent when the episode reward exceeds 499. Save the agent to a folder called savedAgents.
trainOpts.SaveAgentCriteria = "EpisodeReward"; trainOpts.SaveAgentValue = 499; trainOpts.SaveAgentDirectory = "savedAgents";
Turn off the command-line display. Turn on the Reinforcement Learning Training Monitor so you can observe the training progress visually.
trainOpts.Verbose = false;
trainOpts.Plots = "training-progress";You are now ready to train the PG agent. For the predefined cart-pole environment used in this example, you can use plot to generate a visualization of the cart-pole system.
plot(env)
When you run this example, both this visualization and the Reinforcement Learning Training Monitor update with each training episode. Place them side by side on your screen to observe the progress, and train the agent. (This computation can take 20 minutes or more.)
trainingInfo = train(agent,env,trainOpts);
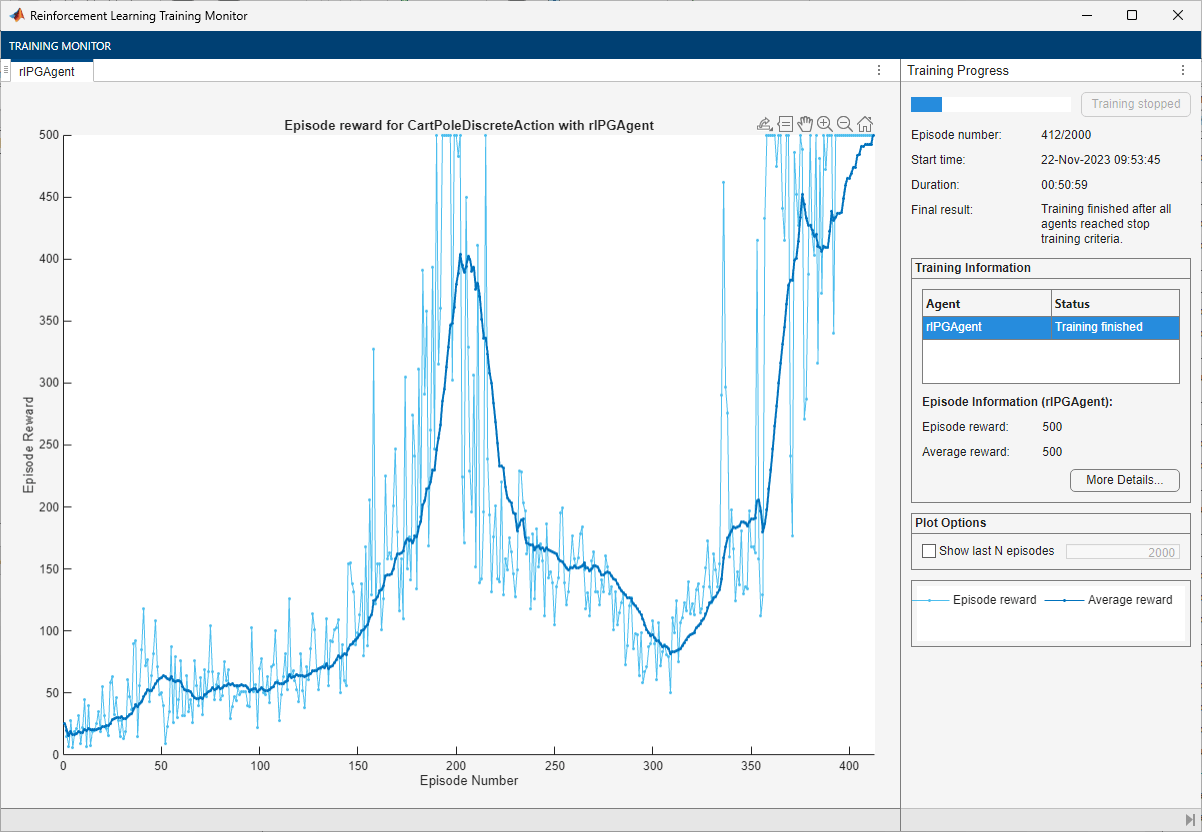
The Reinforcement Learning Training Monitor shows that the training successfully reaches the termination condition of a reward of 500 averaged over the previous five episodes. At each training episode, train updates agent with the parameters learned in the previous episode. When training terminates, you can simulate the environment with the trained agent to evaluate its performance. The environment plot updates during simulation as it did during training.
simOptions = rlSimulationOptions(MaxSteps=500); experience = sim(env,agent,simOptions);
During training, train saves to disk any agents that meet the condition specified with trainOps.SaveAgentCritera and trainOpts.SaveAgentValue. To test the performance of any of those agents, you can load the data from the data files in the folder you specified using trainOpts.SaveAgentDirectory, and simulate the environment with that agent.
This example shows how to periodically evaluate an agent during training using an rlEvaluator object.
Load the predefined environment object representing a cart-pole system with a discrete action space. For more information on this environment, see Use Predefined Control System Environments.
env = rlPredefinedEnv("CartPole-Discrete");The constructor functions initialize the agent networks randomly. Ensure reproducibility of the section by fixing the seed of the random generator.
rng(0)
Create a DQN agent with default networks.
agent = rlDQNAgent(getObservationInfo(env),getActionInfo(env));
Use the standard algorithm instead of the double DQN and configure agent options for training.
agent.AgentOptions.UseDoubleDQN = false; agent.AgentOptions.CriticOptimizerOptions.LearnRate = 1e-3; agent.AgentOptions.CriticOptimizerOptions.GradientThreshold = 5; agent.AgentOptions.MiniBatchSize = 128; agent.AgentOptions.DiscountFactor = 0.99; agent.AgentOptions.TargetSmoothFactor = 5e-3; agent.AgentOptions.ExperienceBufferLength = 1e5; agent.AgentOptions.SampleTime = env.Ts;
To specify training options, create an rlTrainingOptions object. Configure training to stop after when the average reward reaches 480.
tngOpts = rlTrainingOptions( ... MaxEpisodes=5000, ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=480);
To evaluate the agent during training, create an rlEvaluator object. Configure the evaluator to run 5 consecutive evaluation episodes every 50 training episodes.
evl = rlEvaluator( ... NumEpisodes=5, ... EvaluationFrequency=50)
evl =
rlEvaluator with properties:
EvaluationStatisticType: "MeanEpisodeReward"
NumEpisodes: 5
MaxStepsPerEpisode: []
UseExplorationPolicy: 0
RandomSeeds: 1
EvaluationFrequency: 50
To train the agent using these evaluation options, pass evl to train. Training this agent is a computationally intensive process that takes several minutes to complete. To save time while running this example, load a pretrained agent by setting doTraining to false. To train the agent yourself, set doTraining to true.
doTraining = false; if doTraining results = train(agent, env, tngOpts, Evaluator=evl); else load("DQNAgent.mat","agent","results"); end

The red stars on the plot indicate the statistic (for this example the average episode reward) collected for the evaluation episodes.
Display the reward accumulated during the last episode.
results.EpisodeReward(end)
ans = 500
This value means that the agent is able to balance the cart-pole system for the whole episode.
Display the size of the evaluation statistic vector returned for each episode.
size(results.EvaluationStatistic)
ans = 1×2
433 1
Display only the finite values, corresponding to the training episodes at the end of which the 5 evaluation episodes are run.
results.EvaluationStatistic(isfinite(results.EvaluationStatistic))
ans = 8×1
4.4000
106.6000
138.4000
110.4000
139.8000
136.8000
186.0000
500.0000
Train the agents configured in the Train Multiple Agents to Perform Collaborative Task example, within the corresponding environment.
Run the script that loads the environment parameters.
rlCollaborativeTaskParams
Load the file containing the agents. For this example, load the agents that have been already trained using decentralized learning.
load decentralizedAgents.matCreate an environment object that uses the Simulink® model rlCollaborativeTask. Because the agent objects referred by the agent blocks are already available in the MATLAB® workspace at the time of environment creation, the observation and action specification arrays are not needed. For more information, see rlSimulinkEnv.
env = rlSimulinkEnv("rlCollaborativeTask", ... ["rlCollaborativeTask/Agent A", "rlCollaborativeTask/Agent B"])
env =
SimulinkEnvWithAgent with properties:
Model : rlCollaborativeTask
AgentBlock : [
rlCollaborativeTask/Agent A
rlCollaborativeTask/Agent B
]
ResetFcn : []
UseFastRestart : on
It is good practice to specify a reset function for the environment such that agents start from random initial positions at the beginning of each episode. For an example, see the resetRobots function defined in Train Multiple Agents to Perform Collaborative Task. For this example, however, do not define a reset function.
For this example, configure the training to be centralized.
Allocate both agents (with indices
1and2) in a single group. Do this by specifying the agent indices in the"AgentGroups"option.Specify the
"centralized"learning strategy.For this example, run the training for 5 episodes, with each episode lasting a maximum of 600 time steps.
Do not visualize training progress.
trainOpts = rlMultiAgentTrainingOptions( ... AgentGroups={[1,2]}, ... LearningStrategy="centralized", ... MaxEpisodes=5, ... MaxStepsPerEpisode=600, ... StopTrainingCriteria="none", ... Plots="none");
Train the agents using the train function.
results = train([dcAgentA,dcAgentB],env,trainOpts);
Replaying the animation plot shows you how the agent behaves in the training.
This example shows how to resume training using existing training data for training Q-learning. For more information on these agents, see Q-Learning Agent and SARSA Agent.
Create Grid World Environment
For this example, create the basic grid world environment.
env = rlPredefinedEnv("BasicGridWorld");To specify that the initial state of the agent is always [2,1], create a reset function that returns the state number for the initial agent state.
x0 = [1:12 15:17 19:22 24]; env.ResetFcn = @() x0(randi(numel(x0)));
Fix the random generator seed for reproducibility.
rng(1)
Create Q-Learning Agent
To create a Q-learning agent, first create a Q table using the observation and action specifications from the grid world environment. Set the learning rate of the representation to 1.
qTable = rlTable(getObservationInfo(env),getActionInfo(env)); qVf = rlQValueFunction( ... qTable, ... getObservationInfo(env), ... getActionInfo(env));
Next, create a Q-learning agent using this table representation and configure the epsilon-greedy exploration. For more information on creating Q-learning agents, see rlQAgent and rlQAgentOptions. Keep the default value of the discount factor to 0.99.
agentOpts = rlQAgentOptions; agentOpts.EpsilonGreedyExploration.Epsilon = 0.2; agentOpts.CriticOptimizerOptions.LearnRate = 0.2; agentOpts.EpsilonGreedyExploration.EpsilonDecay = 1e-3; agentOpts.EpsilonGreedyExploration.EpsilonMin = 1e-3; agentOpts.DiscountFactor = 1; qAgent = rlQAgent(qVf,agentOpts);
Train Q-Learning Agent for 100 Episodes
To train the agent, first specify the training options. For more information on training options, see rlTrainingOptions.
trainOpts = rlTrainingOptions; trainOpts.MaxStepsPerEpisode = 200; trainOpts.MaxEpisodes = 1e6; trainOpts.Plots = "none"; trainOpts.Verbose = false; trainOpts.StopTrainingCriteria = "EpisodeCount"; trainOpts.StopTrainingValue = 100; trainOpts.ScoreAveragingWindowLength = 30;
Train the Q-learning agent using the train function. Training can take several minutes to complete. To save time while running this example, load a pretrained agent by setting doTraining to false. To train the agent yourself, set doTraining to true.
trainingStats = train(qAgent,env,trainOpts);
Display index of last episode.
trainingStats.EpisodeIndex(end)
ans = 100
Train Q-Learning Agent for 200 More Episodes
Set the training to stop after episode 300.
trainingStats.TrainingOptions.StopTrainingValue = 300;
Resume the training using the training data that exists in trainingStats.
trainingStats = train(qAgent,env,trainingStats);
Display index of last episode.
trainingStats.EpisodeIndex(end)
ans = 300
Plot episode reward.
figure() plot(trainingStats.EpisodeIndex,trainingStats.EpisodeReward) title("Episode Reward") xlabel("EpisodeIndex") ylabel("EpisodeReward")

Display the final Q-value table.
qAgentFinalQ = getLearnableParameters(getCritic(qAgent));
qAgentFinalQ{1}ans = 25×4 single matrix
-5.9934 5.4707 10.0000 1.6349
8.9968 -4.5969 -4.7967 -8.0369
-3.9844 8.0000 -4.3924 -6.3623
-4.4457 -3.4794 9.0000 -4.1959
-4.4743 -2.3964 7.0000 1.7904
-4.5117 -3.7606 11.0000 -1.3847
-3.5016 6.8809 12.0000 4.0197
11.0000 -3.8480 0.6307 -3.0320
10.0000 7.0000 -1.5601 -3.4550
3.0709 4.2059 8.0000 4.8305
3.7218 12.0000 -2.4565 0.1225
5.1674 7.1212 13.0000 5.3067
0 0 0 0
0 0 0 0
-3.6720 1.0094 9.0000 6.0811
⋮
Validate Q-Learning Results
To validate the training results, simulate the agent in the training environment.
By default, the agent uses a greedy (hence deterministic) policy in simulation. To use the exploratory policy instead, set the UseExplorationPolicy agent property to true.
Before running the simulation, visualize the environment and configure the visualization to maintain a trace of the agent states.
plot(env) env.ResetFcn = @() 2; env.Model.Viewer.ShowTrace = true; env.Model.Viewer.clearTrace;
Simulate the agent in the environment using the sim function.
experience = sim(qAgent,env);

Display the total reward.
totalRwd = sum(experience.Reward)
totalRwd = 9
Input Arguments
Name-Value Arguments
Output Arguments
Tips
trainupdates the agents as training progresses. To preserve the original agent parameters for later use, save the agents to a MAT file.By default, calling
trainopens the Reinforcement Learning Training Monitor, which lets you visualize the progress of the training. The Reinforcement Learning Training Monitor plot shows the reward for each episode, a running average reward value, and the critic estimate Q0 (for agents that have critics). The Reinforcement Learning Training Monitor also displays several episode and training statistics. To turn off the Reinforcement Learning Training Monitor, set thePlotsoption oftrainOptsto"none".If you use a predefined environment for which there is a visualization, you can use
plot(env)to visualize the environment. If you callplot(env)before training, then the visualization updates during training to allow you to visualize the progress of each episode. (For custom environments, you must implement your ownplotmethod.)Training terminates when the conditions specified in
trainOptsare satisfied. To terminate training in progress, in the Reinforcement Learning Training Monitor, click Stop Training. Becausetrainupdates the agent at each episode, you can resume training by callingtrain(agent,env,trainOpts)again, without losing the trained parameters learned during the first call totrain.During training, you can save candidate agents that meet conditions you specify with
trainOpts. For instance, you can save any agent whose episode reward exceeds a certain value, even if the overall condition for terminating training is not yet satisfied.trainstores saved agents in a MAT file in the folder you specify withtrainOpts. Saved agents can be useful, for instance, to allow you to test candidate agents generated during a long-running training process. For details about saving criteria and saving location, seerlTrainingOptions.
Algorithms
In general, train performs the following iterative steps:
Initialize
agent.For each episode:
Reset the environment.
Get the initial observation s0 from the environment.
Compute the initial action a0 = μ(s0).
Set the current action to the initial action (a←a0) and set the current observation to the initial observation (s←s0).
While the episode is not finished or terminated:
Step the environment with action a to obtain the next observation s' and the reward r.
Learn from the experience set (s,a,r,s').
Compute the next action a' = μ(s').
Update the current action with the next action (a←a') and update the current observation with the next observation (s←s').
Break if the episode termination conditions defined in the environment are met.
If the training termination condition defined by
trainOptsis met, terminate training. Otherwise, begin the next episode.
The specifics of how the software performs these steps depend on the configuration of the agent and environment. For instance, resetting the environment at the start of each episode can include randomizing initial state values, if you configure your environment to do so. For more information on agents and their training algorithms, see Reinforcement Learning Agents. To use parallel processing and GPUs to speed up training, see Train Agents Using Parallel Computing and GPUs.