read
Syntax
Description
[
returns depth and image data of the image that is captured with the camera specified by
image,depth] = read(camera)camera in the simulation 3D environment. To enable the
depth output argument, set the EnableDepthOutput
argument of the sim3d.sensors.Camera object to
true.
[
returns semantic and image data of the image that is captured with the camera specified by
image,semantic] = read(camera)camera in the simulation 3D environment. To enable the
semantic output argument, set the EnableSemanticOutput argument of sim3d.sensors.Camera
object to true.
[
returns depth, semantic, and image data of the image that is captured with the camera
specified by image,depth,semantic] = read(camera)camera in the simulation 3D environment. To enable the
depth and semantic output arguments, set the
EnableDepthOutput
and EnableSemanticOutput arguments of the sim3d.sensors.Camera
object to true. You can use these images to visualize and verify your
driving algorithms. You can also develop depth estimation and semantic segmentation
algorithms.
Examples
Since R2025a
Create a camera in the 3D environment using the sim3d.sensors.Camera object. You can capture images of the 3D environment and display them in MATLAB®. Use the read function to extract image data from the 3D environment.
Create a 3D environment and set up communication with the Unreal Engine simulation environment using the output function OutputImpl and the update function UpdateImpl. The sim3d.World object can send and receive data about the 3D environment to and from the Unreal Engine at each simulation step using output and update functions, respectively. Before the Unreal Engine simulates, MATLAB calls the output function and sends data to the Unreal Engine. Then, the Unreal Engine executes at each time step and sends data to MATLAB in the update function. You can use the update function to read this data or change values after each simulation step.
world = sim3d.World(Output=@outputImpl,Update=@updateImpl);
Create a box actor in the 3D environment using the sim3d.Actor object and add the box to the world.
cube = sim3d.Actor( ... ActorName="Cube", ... Mobility='Movable'); createShape(cube,"box"); add(world,cube);
Create a camera object using the sim3d.sensors.Camera object and set the location of the camera using the Translation property. Add the camera to the world.
camera = sim3d.sensors.Camera( ... ActorName="Camera"); camera.Translation = [-3 0 0]; add(world,camera);
Run the co-simulation.
sampletime = 1/60; stoptime = 2; run(world,sampletime,stoptime);

Output Function
The output function sends data about the actor to the Unreal Engine environment at each simulation step. For this example, the function rotates the Cube about its Z-axis by updating the Rotation property of the Cube at each simulation step.
function outputImpl(world) world.Actors.Cube.Rotation(3) = world.Actors.Cube.Rotation(3) ... + 0.01; end
Update Function
The update function reads data from the Unreal Engine environment at each simulation step. For this example, the update function uses the read function of the sim3d.sensors.Camera object to get image data from the Camera in the Unreal Engine environment and uses the image function to display it in MATLAB.
function updateImpl(world) sceneImage = read(world.Actors.Camera); image(sceneImage); end
Since R2025a
Generate depth and semantic data for the 3D environment. Create a camera in the 3D environment using the sim3d.sensors.Camera object. You can capture images, generate depth and semantic data for the 3D environment and, display the images in MATLAB®. Use the read function to generate the depth and semantic data for the 3D environment.
Create figure windows and specify the name using the figure function.
imageFigure = figure(Name="Image"); depthFigure = figure(Name="Depth"); semanticFigure = figure(Name="Semantic");
Create a 3D environment using the sim3d.World object. Set up communication with the Unreal Engine simulation environment using the output function OutputImpl and the update function UpdateImpl. An anonymous function is defined using @(world), where world is the current state of the sim3d.World object during each simulation step. This function calls the UpdateImpl function, which takes world and the figure window handles imageFigure, depthFigure, and semanticFigure as arguments.
world = sim3d.World( ... Output=@OutputImpl, ... Update=@(world) UpdateImpl(world,imageFigure, ... depthFigure,semanticFigure));
Create a box actor in the 3D environment using the sim3d.Actor object and add the box to the world.
cube = sim3d.Actor( ... ActorName="Cube", ... Mobility='Movable'); createShape(cube,"box"); add(world,cube);
Create a camera object with depth and semantic data using the sim3d.sensors.Camera object. Set the location of the camera using the Translation property. Add the camera to the world.
camera = sim3d.sensors.Camera( ... ActorName="Camera", ... EnableDepthOutput = true, ... EnableSemanticOutput = true); camera.Translation = [-3 0 0]; add(world,camera);
Run the co-simulation. The software displays the image, depth, and semantic data in MATLAB.
sampletime = 1/60; stoptime = 2; run(world,sampletime,stoptime);

Output Function
The output function sends data about the actor to the Unreal Engine environment at each simulation step. For this example, the function rotates the Cube about its Z-axis by updating the Rotation property of the Cube at each simulation step.
function OutputImpl(world) world.Actors.Cube.Rotation(3) = world.Actors.Cube.Rotation(3) ... + 0.01; end
Update Function
The update function reads data from the Unreal Engine environment and updates the content in the figure windows at each simulation step. For this example, the update function uses the read function of the sim3d.sensors.Camera object to get the image, depth, and semantic data from the Camera in the Unreal Engine environment and uses the image and imagesc functions to display the data in MATLAB.
function UpdateImpl(world,imageFigure,depthFigure,semanticFigure) [sceneImage, sceneDepth, sceneSemantic] = read(world.Actors.Camera); figure(imageFigure); image(sceneImage); figure(depthFigure); sceneDepth(sceneDepth > 20) = nan; imagesc(sceneDepth); figure(semanticFigure) image(sceneSemantic) end
Input Arguments
Output Arguments
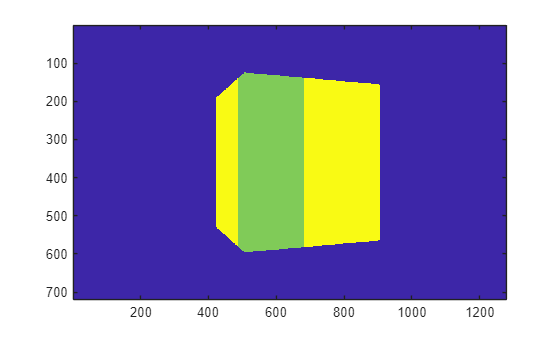
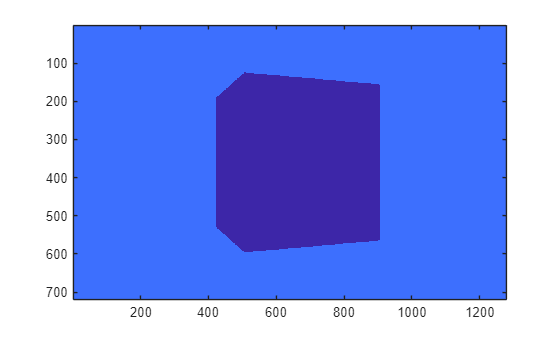
The table summarizes each type of output data and how to enable it.
| Output | Description | Argument to Enable Output | Sample Visualization |
|---|---|---|---|
| RGB image data captured by the camera | Not applicable |
|
| Depth map with values from 0 m to 1000 meters |
|
|
| Semantic segmentation map of label IDs that correspond to objects in the scene |
|
|



Image data returned by camera, returned as an m-by-n-by-3 array of RGB triplet values. m is the vertical resolution of the image. n is the horizontal resolution of the image.
Data Types: uint8
Object depth for each pixel in the image, returned as an m-by-n array. m is the vertical resolution of the image. n is the horizontal resolution of the image. Depth is in the range from 0 to 1000 meters.
Dependencies
To enable depth output, set the EnableDepthOutput argument of the
sim3d.sensors.Camera object to 1.
Semantic
label identifier for each pixel in the image, output as an
m-by-n array of RGB triplet values.
m is the vertical resolution of the image. n is the
horizontal resolution of the image. The table shows the object IDs used in the default scenes.
If a scene contains an object that does not have an assigned ID, that object is assigned an ID
of 0. If you are using a custom scene, in the Unreal® Editor, you can assign new object types to unused IDs. The detection of lane
markings is not supported.
| ID | Type |
|---|---|
0 | None/default |
1 | Building |
2 | Not used |
3 | Other |
4 | Pedestrians |
5 | Pole |
6 | Lane markings |
7 | Road |
8 | Sidewalk |
9 | Vegetation |
10 | Vehicle |
11 | Not used |
12 | Generic traffic sign |
13 | Stop sign |
14 | Yield sign |
15 | Speed limit sign |
16 | Weight limit sign |
17-18 | Not used |
19 | Left and right arrow warning sign |
20 | Left chevron warning sign |
21 | Right chevron warning sign |
22 | Not used |
23 | Right one-way sign |
24 | Not used |
25 | School bus only sign |
26-38 | Not used |
39 | Crosswalk sign |
40 | Not used |
41 | Traffic signal |
42 | Curve right warning sign |
43 | Curve left warning sign |
44 | Up right arrow warning sign |
45-47 | Not used |
48 | Railroad crossing sign |
49 | Street sign |
50 | Roundabout warning sign |
51 | Fire hydrant |
52 | Exit sign |
53 | Bike lane sign |
54-56 | Not used |
57 | Sky |
58 | Curb |
59 | Flyover ramp |
60 | Road guard rail |
| 61 | Bicyclist |
62-66 | Not used |
67 | Deer |
68-70 | Not used |
71 | Barricade |
72 | Motorcycle |
73-255 | Not used |
Dependencies
To enable semantic output, set the EnableSemanticOutput argument of the
sim3d.sensors.Camera object to 1.
Version History
Introduced in R2024b