edge
Classification edge for neural network classifier
Description
e = edge(Mdl,Tbl,ResponseVarName)Mdl using the predictor
data in table Tbl and the class labels in the
ResponseVarName table variable.
e is returned as a scalar value that represents the mean of the
classification margins.
e = edge(___,Name,Value)
Note
If the predictor data X or the predictor variables in
Tbl contain any missing values, the
edge function can return NaN. For more
details, see edge can return NaN for predictor data with missing values.
Examples
Calculate the test set classification edge of a neural network classifier.
Load the patients data set. Create a table from the data set. Each row corresponds to one patient, and each column corresponds to a diagnostic variable. Use the Smoker variable as the response variable, and the rest of the variables as predictors.
load patients
tbl = table(Diastolic,Systolic,Gender,Height,Weight,Age,Smoker);Separate the data into a training set tblTrain and a test set tblTest by using a stratified holdout partition. The software reserves approximately 30% of the observations for the test data set and uses the rest of the observations for the training data set.
rng("default") % For reproducibility of the partition c = cvpartition(tbl.Smoker,"Holdout",0.30); trainingIndices = training(c); testIndices = test(c); tblTrain = tbl(trainingIndices,:); tblTest = tbl(testIndices,:);
Train a neural network classifier using the training set. Specify the Smoker column of tblTrain as the response variable. Specify to standardize the numeric predictors.
Mdl = fitcnet(tblTrain,"Smoker", ... "Standardize",true);
Calculate the test set classification edge.
e = edge(Mdl,tblTest,"Smoker")e = 0.8657
The mean of the classification margins is close to 1, which indicates that the model performs well overall.
Perform feature selection by comparing test set classification margins, edges, errors, and predictions. Compare the test set metrics for a model trained using all the predictors to the test set metrics for a model trained using only a subset of the predictors.
Load the sample file fisheriris.csv, which contains iris data including sepal length, sepal width, petal length, petal width, and species type. Read the file into a table.
fishertable = readtable('fisheriris.csv');Separate the data into a training set trainTbl and a test set testTbl by using a stratified holdout partition. The software reserves approximately 30% of the observations for the test data set and uses the rest of the observations for the training data set.
rng("default") c = cvpartition(fishertable.Species,"Holdout",0.3); trainTbl = fishertable(training(c),:); testTbl = fishertable(test(c),:);
Train one neural network classifier using all the predictors in the training set, and train another classifier using all the predictors except PetalWidth. For both models, specify Species as the response variable, and standardize the predictors.
allMdl = fitcnet(trainTbl,"Species","Standardize",true); subsetMdl = fitcnet(trainTbl,"Species ~ SepalLength + SepalWidth + PetalLength", ... "Standardize",true);
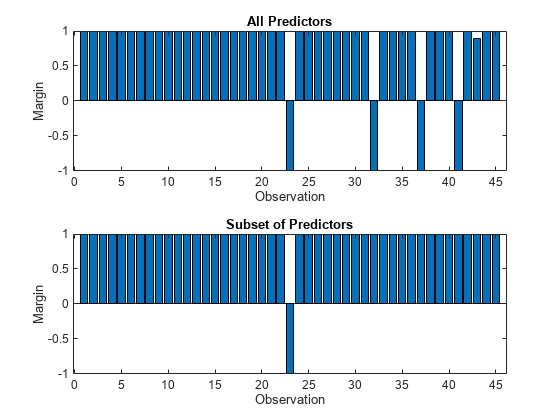
Calculate the test set classification margins for the two models. Because the test set includes only 45 observations, display the margins using bar graphs.
For each observation, the classification margin is the difference between the classification score for the true class and the maximal score for the false classes. Because neural network classifiers return classification scores that are posterior probabilities, margin values close to 1 indicate confident classifications and negative margin values indicate misclassifications.
tiledlayout(2,1) % Top axes ax1 = nexttile; allMargins = margin(allMdl,testTbl); bar(ax1,allMargins) xlabel(ax1,"Observation") ylabel(ax1,"Margin") title(ax1,"All Predictors") % Bottom axes ax2 = nexttile; subsetMargins = margin(subsetMdl,testTbl); bar(ax2,subsetMargins) xlabel(ax2,"Observation") ylabel(ax2,"Margin") title(ax2,"Subset of Predictors")
Compare the test set classification edge, or mean of the classification margins, of the two models.
allEdge = edge(allMdl,testTbl)
allEdge = 0.8198
subsetEdge = edge(subsetMdl,testTbl)
subsetEdge = 0.9556
Based on the test set classification margins and edges, the model trained on a subset of the predictors seems to outperform the model trained on all the predictors.
Compare the test set classification error of the two models.
allError = loss(allMdl,testTbl); allAccuracy = 1-allError
allAccuracy = 0.9111
subsetError = loss(subsetMdl,testTbl); subsetAccuracy = 1-subsetError
subsetAccuracy = 0.9778
Again, the model trained using only a subset of the predictors seems to perform better than the model trained using all the predictors.
Visualize the test set classification results using confusion matrices.
allLabels = predict(allMdl,testTbl);
figure
confusionchart(testTbl.Species,allLabels)
title("All Predictors")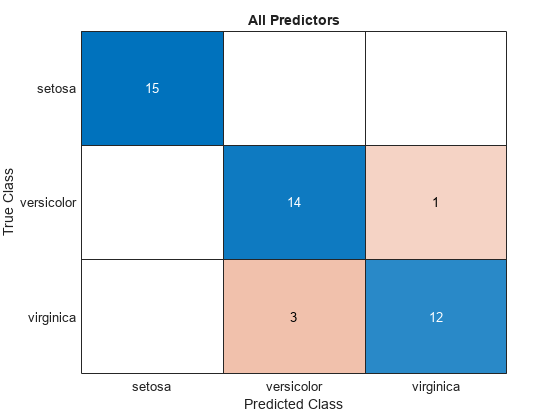
subsetLabels = predict(subsetMdl,testTbl);
figure
confusionchart(testTbl.Species,subsetLabels)
title("Subset of Predictors")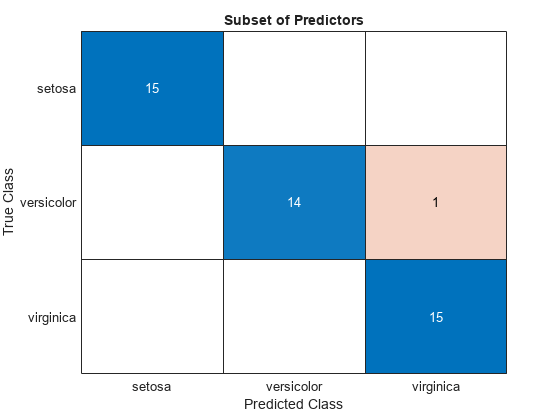
The model trained using all the predictors misclassifies four of the test set observations. The model trained using a subset of the predictors misclassifies only one of the test set observations.
Given the test set performance of the two models, consider using the model trained using all the predictors except PetalWidth.