fitlm
Fit linear regression model
Syntax
Description
mdl = fitlm(tbl,ResponseVarName)
mdl = fitlm(___,Name=Value)
Examples
Fit a linear regression model using a matrix input data set.
Load the carsmall data set, a matrix input data set.
load carsmall
X = [Weight,Horsepower,Acceleration];Fit a linear regression model by using fitlm.
mdl = fitlm(X,MPG)
mdl =
Linear regression model:
y ~ 1 + x1 + x2 + x3
Estimated Coefficients:
Estimate SE tStat pValue
__________ _________ _________ __________
(Intercept) 47.977 3.8785 12.37 4.8957e-21
x1 -0.0065416 0.0011274 -5.8023 9.8742e-08
x2 -0.042943 0.024313 -1.7663 0.08078
x3 -0.011583 0.19333 -0.059913 0.95236
Number of observations: 93, Error degrees of freedom: 89
Root Mean Squared Error: 4.09
R-squared: 0.752, Adjusted R-Squared: 0.744
F-statistic vs. constant model: 90, p-value = 7.38e-27
The model display includes the model formula, estimated coefficients, and model summary statistics.
The model formula in the display, y ~ 1 + x1 + x2 + x3, corresponds to . For more information, see Wilkinson Notation.
The model display also shows the estimated coefficient information, which is stored in the Coefficients property. Display the Coefficients property.
mdl.Coefficients
ans=4×4 table
Estimate SE tStat pValue
__________ _________ _________ __________
(Intercept) 47.977 3.8785 12.37 4.8957e-21
x1 -0.0065416 0.0011274 -5.8023 9.8742e-08
x2 -0.042943 0.024313 -1.7663 0.08078
x3 -0.011583 0.19333 -0.059913 0.95236
The Coefficient property includes these columns:
Estimate— Coefficient estimates for each corresponding term in the model. For example, the estimate for the constant term (intercept) is 47.977.SE— Standard error of the coefficients.tStat— t-statistic for each coefficient to test the null hypothesis that the corresponding coefficient is zero against the alternative that it is different from zero, given the other predictors in the model. Note thattStat = Estimate/SE. For example, the t-statistic for the intercept is 47.977/3.8785 = 12.37.pValue— p-value for the t-statistic of the two-sided hypothesis test. For example, the p-value of the t-statistic forx2is greater than 0.05, so this term is not significant at the 5% significance level given the other terms in the model.
The summary statistics of the model are:
Number of observations— Number of rows without anyNaNvalues. For example,Number of observationsis 93 because theMPGdata vector has sixNaNvalues and theHorsepowerdata vector has oneNaNvalue for a different observation, where the number of rows inXandMPGis 100.Error degrees of freedom— n – p, where n is the number of observations, and p is the number of coefficients in the model, including the intercept. For example, the model has four predictors, so theError degrees of freedomis 93 – 4 = 89.Root mean squared error— Square root of the mean squared error, which estimates the standard deviation of the error distribution.R-squaredandAdjusted R-squared— Coefficient of determination and adjusted coefficient of determination, respectively. For example, theR-squaredvalue suggests that the model explains approximately 75% of the variability in the response variableMPG.F-statistic vs. constant model— Test statistic for the F-test on the regression model, which tests whether the model fits significantly better than a degenerate model consisting of only a constant term.p-value— p-value for the F-test on the model. For example, the model is significant with a p-value of 7.3816e-27.
You can find these statistics in the model properties (NumObservations, DFE, RMSE, and Rsquared) and by using the anova function.
anova(mdl,'summary')ans=3×5 table
SumSq DF MeanSq F pValue
______ __ ______ ______ __________
Total 6004.8 92 65.269
Model 4516 3 1505.3 89.987 7.3816e-27
Residual 1488.8 89 16.728
Use plot to create an added variable plot (partial regression leverage plot) for the whole model except the constant (intercept) term.
plot(mdl)
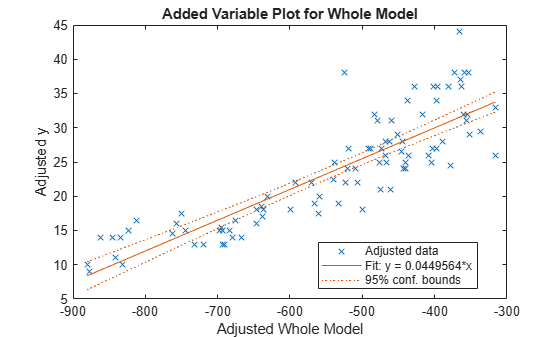
Load the sample data.
load carsmallStore the variables in a table.
tbl = table(Weight,Acceleration,MPG,'VariableNames',{'Weight','Acceleration','MPG'});
Display the first five rows of the table.
tbl(1:5,:)
ans=5×3 table
Weight Acceleration MPG
______ ____________ ___
3504 12 18
3693 11.5 15
3436 11 18
3433 12 16
3449 10.5 17
Fit a linear regression model for miles per gallon (MPG). Specify the model formula by using Wilkinson Notation.
lm = fitlm(tbl,'MPG~Weight+Acceleration')lm =
Linear regression model:
MPG ~ 1 + Weight + Acceleration
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ _______ __________
(Intercept) 45.155 3.4659 13.028 1.6266e-22
Weight -0.0082475 0.00059836 -13.783 5.3165e-24
Acceleration 0.19694 0.14743 1.3359 0.18493
Number of observations: 94, Error degrees of freedom: 91
Root Mean Squared Error: 4.12
R-squared: 0.743, Adjusted R-Squared: 0.738
F-statistic vs. constant model: 132, p-value = 1.38e-27
The model 'MPG~Weight+Acceleration' in this example is equivalent to set the model specification as 'linear'. For example,
lm2 = fitlm(tbl,'linear');If you use a character vector for model specification and you do not specify the response variable, then fitlm accepts the last variable in tbl as the response variable and the other variables as the predictor variables.
Fit a linear regression model using a model formula specified by Wilkinson notation.
Load the sample data.
load carsmallStore the variables in a table.
tbl = table(Weight,Acceleration,Model_Year,MPG,'VariableNames',{'Weight','Acceleration','Model_Year','MPG'});
Fit a linear regression model for miles per gallon (MPG) with weight and acceleration as the predictor variables. Specify the model formula by using Wilkinson Notation.
lm = fitlm(tbl,'MPG~Weight+Acceleration')lm =
Linear regression model:
MPG ~ 1 + Weight + Acceleration
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ _______ __________
(Intercept) 45.155 3.4659 13.028 1.6266e-22
Weight -0.0082475 0.00059836 -13.783 5.3165e-24
Acceleration 0.19694 0.14743 1.3359 0.18493
Number of observations: 94, Error degrees of freedom: 91
Root Mean Squared Error: 4.12
R-squared: 0.743, Adjusted R-Squared: 0.738
F-statistic vs. constant model: 132, p-value = 1.38e-27
The p-value of 0.18493 indicates that Acceleration does not have a significant impact on MPG.
Remove Acceleration from the model, and try improving the model by adding the predictor variable Model_Year. First define Model_Year as a categorical variable.
tbl.Model_Year = categorical(tbl.Model_Year);
lm = fitlm(tbl,'MPG~Weight+Model_Year')lm =
Linear regression model:
MPG ~ 1 + Weight + Model_Year
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ _______ __________
(Intercept) 40.11 1.5418 26.016 1.2024e-43
Weight -0.0066475 0.00042802 -15.531 3.3639e-27
Model_Year_76 1.9291 0.74761 2.5804 0.011488
Model_Year_82 7.9093 0.84975 9.3078 7.8681e-15
Number of observations: 94, Error degrees of freedom: 90
Root Mean Squared Error: 2.92
R-squared: 0.873, Adjusted R-Squared: 0.868
F-statistic vs. constant model: 206, p-value = 3.83e-40
Specifying modelspec using Wilkinson notation enables you to update the model without having to change the design matrix. fitlm uses only the variables that are specified in the formula. It also creates the necessary two dummy indicator variables for the categorical variable Model_Year.
Fit a linear regression model using a terms matrix.
Terms Matrix for Table Input
If the model variables are in a table, then a column of 0s in a terms matrix represents the position of the response variable.
Load the hospital data set.
load hospitalStore the variables in a table.
t = table(hospital.Sex,hospital.BloodPressure(:,1),hospital.Age,hospital.Smoker, ... 'VariableNames',{'Sex','BloodPressure','Age','Smoker'});
Represent the linear model 'BloodPressure ~ 1 + Sex + Age + Smoker' using a terms matrix. The response variable is in the second column of the table, so the second column of the terms matrix must be a column of 0s for the response variable.
T = [0 0 0 0;1 0 0 0;0 0 1 0;0 0 0 1]
T = 4×4
0 0 0 0
1 0 0 0
0 0 1 0
0 0 0 1
Fit a linear model.
mdl1 = fitlm(t,T)
mdl1 =
Linear regression model:
BloodPressure ~ 1 + Sex + Age + Smoker
Estimated Coefficients:
Estimate SE tStat pValue
________ ________ ________ __________
(Intercept) 116.14 2.6107 44.485 7.1287e-66
Sex_Male 0.050106 0.98364 0.050939 0.95948
Age 0.085276 0.066945 1.2738 0.2058
Smoker_1 9.87 1.0346 9.5395 1.4516e-15
Number of observations: 100, Error degrees of freedom: 96
Root Mean Squared Error: 4.78
R-squared: 0.507, Adjusted R-Squared: 0.492
F-statistic vs. constant model: 33, p-value = 9.91e-15
Terms Matrix for Matrix Input
If the predictor and response variables are in a matrix and column vector, then you must include 0 for the response variable at the end of each row in a terms matrix.
Load the carsmall data set and define the matrix of predictors.
load carsmall
X = [Acceleration,Weight];Specify the model 'MPG ~ Acceleration + Weight + Acceleration:Weight + Weight^2' using a terms matrix. This model includes the main effect and two-way interaction terms for the variables Acceleration and Weight, and a second-order term for the variable Weight.
T = [0 0 0;1 0 0;0 1 0;1 1 0;0 2 0]
T = 5×3
0 0 0
1 0 0
0 1 0
1 1 0
0 2 0
Fit a linear model.
mdl2 = fitlm(X,MPG,T)
mdl2 =
Linear regression model:
y ~ 1 + x1*x2 + x2^2
Estimated Coefficients:
Estimate SE tStat pValue
___________ __________ _______ __________
(Intercept) 48.906 12.589 3.8847 0.00019665
x1 0.54418 0.57125 0.95261 0.34337
x2 -0.012781 0.0060312 -2.1192 0.036857
x1:x2 -0.00010892 0.00017925 -0.6076 0.545
x2^2 9.7518e-07 7.5389e-07 1.2935 0.19917
Number of observations: 94, Error degrees of freedom: 89
Root Mean Squared Error: 4.1
R-squared: 0.751, Adjusted R-Squared: 0.739
F-statistic vs. constant model: 67, p-value = 4.99e-26
Only the intercept and x2 term, which corresponds to the Weight variable, are significant at the 5% significance level.
Fit a linear regression model that contains a categorical predictor. Reorder the categories of the categorical predictor to control the reference level in the model. Then, use anova to test the significance of the categorical variable.
Model with Categorical Predictor
Load the carsmall data set and create a linear regression model of MPG as a function of Model_Year. To treat the numeric vector Model_Year as a categorical variable, identify the predictor using the 'CategoricalVars' name-value pair argument.
load carsmall mdl = fitlm(Model_Year,MPG,'CategoricalVars',1,'VarNames',{'Model_Year','MPG'})
mdl =
Linear regression model:
MPG ~ 1 + Model_Year
Estimated Coefficients:
Estimate SE tStat pValue
________ ______ ______ __________
(Intercept) 17.69 1.0328 17.127 3.2371e-30
Model_Year_76 3.8839 1.4059 2.7625 0.0069402
Model_Year_82 14.02 1.4369 9.7571 8.2164e-16
Number of observations: 94, Error degrees of freedom: 91
Root Mean Squared Error: 5.56
R-squared: 0.531, Adjusted R-Squared: 0.521
F-statistic vs. constant model: 51.6, p-value = 1.07e-15
The model formula in the display, MPG ~ 1 + Model_Year, corresponds to
,
where and are indicator variables whose value is one if the value of Model_Year is 76 and 82, respectively. For more information about the model formula, see Wilkinson Notation. The Model_Year variable includes three distinct values, which you can check by using the unique function.
unique(Model_Year)
ans = 3×1
70
76
82
fitlm chooses the smallest value in Model_Year as a reference level ('70') and creates two indicator variables and . The model includes only two indicator variables because the design matrix becomes rank deficient if the model includes three indicator variables (one for each level) and an intercept term.
Model with Full Indicator Variables
You can interpret the model formula of mdl as a model that has three indicator variables without an intercept term:
.
Alternatively, you can create a model that has three indicator variables without an intercept term by manually creating indicator variables and specifying the model formula.
temp_Year = dummyvar(categorical(Model_Year));
Model_Year_70 = temp_Year(:,1);
Model_Year_76 = temp_Year(:,2);
Model_Year_82 = temp_Year(:,3);
tbl = table(Model_Year_70,Model_Year_76,Model_Year_82,MPG);
mdl = fitlm(tbl,'MPG ~ Model_Year_70 + Model_Year_76 + Model_Year_82 - 1')mdl =
Linear regression model:
MPG ~ Model_Year_70 + Model_Year_76 + Model_Year_82
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ______ __________
Model_Year_70 17.69 1.0328 17.127 3.2371e-30
Model_Year_76 21.574 0.95387 22.617 4.0156e-39
Model_Year_82 31.71 0.99896 31.743 5.2234e-51
Number of observations: 94, Error degrees of freedom: 91
Root Mean Squared Error: 5.56
Choose Reference Level in Model
You can choose a reference level by modifying the order of categories in a categorical variable. First, create a categorical variable Year.
Year = categorical(Model_Year);
Check the order of categories by using the categories function.
categories(Year)
ans = 3×1 cell
{'70'}
{'76'}
{'82'}
If you use Year as a predictor variable, then fitlm chooses the first category '70' as a reference level. Reorder Year by using the reordercats function.
Year_reordered = reordercats(Year,{'76','70','82'});
categories(Year_reordered)ans = 3×1 cell
{'76'}
{'70'}
{'82'}
The first category of Year_reordered is '76'. Create a linear regression model of MPG as a function of Year_reordered.
mdl2 = fitlm(Year_reordered,MPG,'VarNames',{'Model_Year','MPG'})
mdl2 =
Linear regression model:
MPG ~ 1 + Model_Year
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ _______ __________
(Intercept) 21.574 0.95387 22.617 4.0156e-39
Model_Year_70 -3.8839 1.4059 -2.7625 0.0069402
Model_Year_82 10.136 1.3812 7.3385 8.7634e-11
Number of observations: 94, Error degrees of freedom: 91
Root Mean Squared Error: 5.56
R-squared: 0.531, Adjusted R-Squared: 0.521
F-statistic vs. constant model: 51.6, p-value = 1.07e-15
mdl2 uses '76' as a reference level and includes two indicator variables and .
Evaluate Categorical Predictor
The model display of mdl2 includes a p-value of each term to test whether or not the corresponding coefficient is equal to zero. Each p-value examines each indicator variable. To examine the categorical variable Model_Year as a group of indicator variables, use anova. Use the 'components'(default) option to return a component ANOVA table that includes ANOVA statistics for each variable in the model except the constant term.
anova(mdl2,'components')ans=2×5 table
SumSq DF MeanSq F pValue
______ __ ______ _____ __________
Model_Year 3190.1 2 1595.1 51.56 1.0694e-15
Error 2815.2 91 30.936
The component ANOVA table includes the p-value of the Model_Year variable, which is smaller than the p-values of the indicator variables.
Fit a linear regression model to sample data. Specify the response and predictor variables, and include only pairwise interaction terms in the model.
Load sample data.
load hospitalFit a linear model with interaction terms to the data. Specify weight as the response variable, and sex, age, and smoking status as the predictor variables. Also, specify that sex and smoking status are categorical variables.
mdl = fitlm(hospital,'interactions','ResponseVar','Weight',... 'PredictorVars',{'Sex','Age','Smoker'},... 'CategoricalVar',{'Sex','Smoker'})
mdl =
Linear regression model:
Weight ~ 1 + Sex*Age + Sex*Smoker + Age*Smoker
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ________ __________
(Intercept) 118.7 7.0718 16.785 6.821e-30
Sex_Male 68.336 9.7153 7.0339 3.3386e-10
Age 0.31068 0.18531 1.6765 0.096991
Smoker_1 3.0425 10.446 0.29127 0.77149
Sex_Male:Age -0.49094 0.24764 -1.9825 0.050377
Sex_Male:Smoker_1 0.9509 3.8031 0.25003 0.80312
Age:Smoker_1 -0.07288 0.26275 -0.27737 0.78211
Number of observations: 100, Error degrees of freedom: 93
Root Mean Squared Error: 8.75
R-squared: 0.898, Adjusted R-Squared: 0.892
F-statistic vs. constant model: 137, p-value = 6.91e-44
The weight of the patients do not seem to differ significantly according to age, or the status of smoking, or interaction of these factors with patient sex at the 5% significance level.
Load the hald data set, which measures the effect of cement composition on its hardening heat.
load haldThis data set includes the variables ingredients and heat. The matrix ingredients contains the percent composition of four chemicals present in the cement. The vector heat contains the values for the heat hardening after 180 days for each cement sample.
Fit a robust linear regression model to the data.
mdl = fitlm(ingredients,heat,'RobustOpts','on')
mdl =
Linear regression model (robust fit):
y ~ 1 + x1 + x2 + x3 + x4
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ________ ________
(Intercept) 60.09 75.818 0.79256 0.4509
x1 1.5753 0.80585 1.9548 0.086346
x2 0.5322 0.78315 0.67957 0.51596
x3 0.13346 0.8166 0.16343 0.87424
x4 -0.12052 0.7672 -0.15709 0.87906
Number of observations: 13, Error degrees of freedom: 8
Root Mean Squared Error: 2.65
R-squared: 0.979, Adjusted R-Squared: 0.969
F-statistic vs. constant model: 94.6, p-value = 9.03e-07
For more details, see the topic Reduce Outlier Effects Using Robust Regression, which compares the results of a robust fit to a standard least-squares fit.
Compute the mean absolute error of a regression model by using 10-fold cross-validation.
Load the carsmall data set. Specify the Acceleration and Displacement variables as predictors and the Weight variable as the response.
load carsmall
X1 = Acceleration;
X2 = Displacement;
y = Weight;Create the custom function regf (shown at the end of this example). This function fits a regression model to training data and then computes predicted car weights on a test set. The function compares the predicted car weight values to the true values, and then computes the mean absolute error (MAE) and the MAE adjusted to the range of the test set car weights.
Note: If you use the live script file for this example, the regf function is already included at the end of the file. Otherwise, you need to create this function at the end of your .m file or add it as a file on the MATLAB® path.
By default, crossval performs 10-fold cross-validation. For each of the 10 training and test set partitions of the data in X1, X2, and y, compute the MAE and adjusted MAE values using the regf function. Find the mean MAE and mean adjusted MAE.
rng('default') % For reproducibility values = crossval(@regf,X1,X2,y)
values = 10×2
319.2261 0.1132
342.3722 0.1240
214.3735 0.0902
174.7247 0.1128
189.4835 0.0832
249.4359 0.1003
194.4210 0.0845
348.7437 0.1700
283.1761 0.1187
210.7444 0.1325
mean(values)
ans = 1×2
252.6701 0.1129
This code creates the function regf.
function errors = regf(X1train,X2train,ytrain,X1test,X2test,ytest) tbltrain = table(X1train,X2train,ytrain, ... 'VariableNames',{'Acceleration','Displacement','Weight'}); tbltest = table(X1test,X2test,ytest, ... 'VariableNames',{'Acceleration','Displacement','Weight'}); mdl = fitlm(tbltrain,'Weight ~ Acceleration + Displacement'); yfit = predict(mdl,tbltest); MAE = mean(abs(yfit-tbltest.Weight)); adjMAE = MAE/range(tbltest.Weight); errors = [MAE adjMAE]; end
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
To access the model properties of the
LinearModelobjectmdl, you can use dot notation. For example,mdl.Residualsreturns a table of the raw, Pearson, Studentized, and standardized residual values for the model.After training a model, you can generate C/C++ code that predicts responses for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
The main fitting algorithm is QR decomposition. For robust fitting,
fitlmuses M-estimation to formulate estimating equations and solves them using the method of Iteratively Reweighted Least Squares (IRLS).fitlmtreats a categorical predictor as follows:A model with a categorical predictor that has L levels (categories) includes L – 1 indicator variables. The model uses the first category as a reference level, so it does not include the indicator variable for the reference level. If the data type of the categorical predictor is
categorical, then you can check the order of categories by usingcategoriesand reorder the categories by usingreordercatsto customize the reference level. For more details about creating indicator variables, see Automatic Creation of Dummy Variables.fitlmtreats the group of L – 1 indicator variables as a single variable. If you want to treat the indicator variables as distinct predictor variables, create indicator variables manually by usingdummyvar. Then use the indicator variables, except the one corresponding to the reference level of the categorical variable, when you fit a model. For the categorical predictorX, if you specify all columns ofdummyvar(X)and an intercept term as predictors, then the design matrix becomes rank deficient.Interaction terms between a continuous predictor and a categorical predictor with L levels consist of the element-wise product of the L – 1 indicator variables with the continuous predictor.
Interaction terms between two categorical predictors with L and M levels consist of the (L – 1)*(M – 1) indicator variables to include all possible combinations of the two categorical predictor levels.
You cannot specify higher-order terms for a categorical predictor because the square of an indicator is equal to itself.
fitlmconsidersNaN,''(empty character vector),""(empty string),<missing>, and<undefined>values intbl,X, andYto be missing values.fitlmdoes not use observations with missing values in the fit. TheObservationInfoproperty of a fitted model indicates whether or notfitlmuses each observation in the fit.
Alternative Functionality
For reduced computation time on high-dimensional data sets, fit a linear regression model using the
fitrlinearfunction.To regularize a regression, use
fitrlinear,lasso,ridge, orplsregress.fitrlinearregularizes a regression for high-dimensional data sets using lasso or ridge regression.lassoremoves redundant predictors in linear regression using lasso or elastic net.ridgeregularizes a regression with correlated terms using ridge regression.plsregressregularizes a regression with correlated terms using partial least squares.
References
[1] DuMouchel, W. H., and F. L. O'Brien. “Integrating a Robust Option into a Multiple Regression Computing Environment.” Computer Science and Statistics: Proceedings of the 21st Symposium on the Interface. Alexandria, VA: American Statistical Association, 1989.
[2] Holland, P. W., and R. E. Welsch. “Robust Regression Using Iteratively Reweighted Least-Squares.” Communications in Statistics: Theory and Methods, A6, 1977, pp. 813–827.
[3] Huber, P. J. Robust Statistics. Hoboken, NJ: John Wiley & Sons, Inc., 1981.
[4] Street, J. O., R. J. Carroll, and D. Ruppert. “A Note on Computing Robust Regression Estimates via Iteratively Reweighted Least Squares.” The American Statistician. Vol. 42, 1988, pp. 152–154.