fitrgp
Fit a Gaussian process regression (GPR) model
Syntax
Description
Mdl = fitrgp(Tbl,ResponseVarName)Tbl, where ResponseVarName is the name of the response variable in Tbl.
Mdl = fitrgp(___,Name=Value)
For example, you can specify the fitting method, the prediction method, the covariance function, or the active set selection method. You can also train a cross-validated model.
Mdl is a RegressionGP object. For
object functions and properties of this object, see RegressionGP.
If you train a cross-validated model, then Mdl is a
RegressionPartitionedGP object. For further analysis on the
cross-validated object, use the object functions of the RegressionPartitionedGP object.
[
also returns Mdl,AggregateOptimizationResults] = fitrgp(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Examples
This example uses the abalone data [1], [2], from the UCI Machine Learning Repository [3]. Download the data and save it in your current folder with the name
abalone.data.
Store the data into a table. Display the first seven rows.
tbl = readtable('abalone.data','Filetype','text',... 'ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height',... 'WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20The dataset has 4177 observations. The goal is to predict the age of abalone from eight physical measurements. The last variable, number of shell rings shows the age of the abalone. The first predictor is a categorical variable. The last variable in the table is the response variable.
Fit a GPR model using the subset of regressors method for parameter estimation and fully independent conditional method for prediction. Standardize the predictors.
gprMdl = fitrgp(tbl,'NoShellRings','KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1)
grMdl =
RegressionGP
PredictorNames: {1x8 cell}
ResponseName: 'Var9'
ResponseTransform: 'none'
NumObservations: 4177
KernelFunction: 'ARDSquaredExponential'
KernelInformation: [1x1 struct]
BasisFunction: 'Constant'
Beta: 10.9148
Sigma: 2.0243
PredictorLocation: [10x1 double]
PredictorScale: [10x1 double]
Alpha: [1000x1 double]
ActiveSetVectors: [1000x10 double]
PredictMethod: 'FIC'
ActiveSetSize: 1000
FitMethod: 'SR'
ActiveSetMethod: 'Random'
IsActiveSetVector: [4177x1 logical]
LogLikelihood: -9.0013e+03
ActiveSetHistory: [1x1 struct]
BCDInformation: []
Predict the responses using the trained model.
ypred = resubPredict(gprMdl);
Plot the true response and the predicted responses.
figure(); plot(tbl.NoShellRings,'r.'); hold on plot(ypred,'b'); xlabel('x'); ylabel('y'); legend({'data','predictions'},'Location','Best'); axis([0 4300 0 30]); hold off;
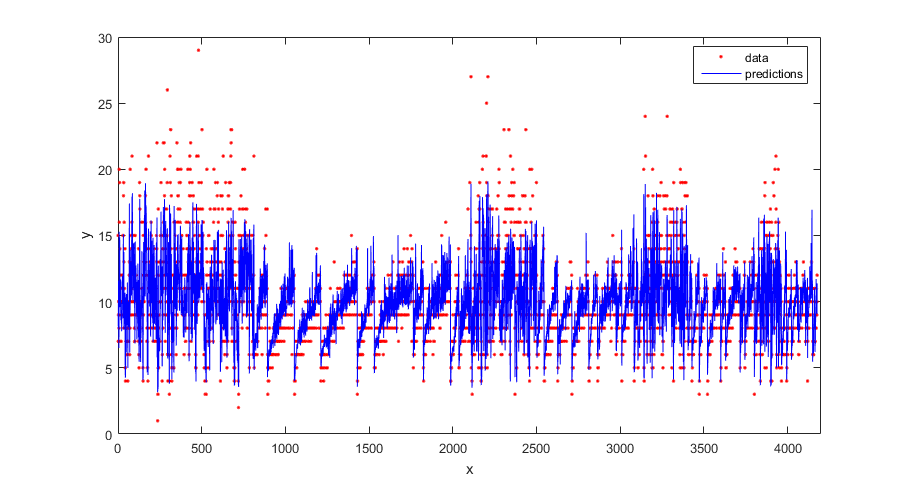
Compute the regression loss on the training data (resubstitution loss) for the trained model.
L = resubLoss(gprMdl)
L =
4.0064Generate sample data.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Fit a GPR model using a linear basis function and the exact fitting method to estimate the parameters. Also use the exact prediction method.
gprMdl = fitrgp(x,y,'Basis','linear',... 'FitMethod','exact','PredictMethod','exact');
Predict the response corresponding to the rows of x (resubstitution predictions) using the trained model.
ypred = resubPredict(gprMdl);
Plot the true response with the predicted values.
plot(x,y,'b.'); hold on; plot(x,ypred,'r','LineWidth',1.5); xlabel('x'); ylabel('y'); legend('Data','GPR predictions'); hold off

Load the sample data.
load('gprdata2.mat')The data has one predictor variable and continuous response. This is simulated data.
Fit a GPR model using the squared exponential kernel function with default kernel parameters.
gprMdl1 = fitrgp(x,y,'KernelFunction','squaredexponential');
Now, fit a second model, where you specify the initial values for the kernel parameters.
sigma0 = 0.2; kparams0 = [3.5, 6.2]; gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential',... 'KernelParameters',kparams0,'Sigma',sigma0);
Compute the resubstitution predictions from both models.
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2);
Plot the response predictions from both models and the responses in training data.
figure(); plot(x,y,'r.'); hold on plot(x,ypred1,'b'); plot(x,ypred2,'g'); xlabel('x'); ylabel('y'); legend({'data','default kernel parameters',... 'kparams0 = [3.5,6.2], sigma0 = 0.2'},... 'Location','Best'); title('Impact of initial kernel parameter values'); hold off
![Figure contains an axes object. The axes object with title Impact of initial kernel parameter values, xlabel x, ylabel y contains 3 objects of type line. One or more of the lines displays its values using only markers These objects represent data, default kernel parameters, kparams0 = [3.5,6.2], sigma0 = 0.2.](../examples/stats/win64/ImpactofSpecifyingInitialKernelParameterValuesExample_01.png)
The marginal log likelihood that fitrgp maximizes to estimate GPR parameters has multiple local solutions; the solution that it converges to depends on the initial point. Each local solution corresponds to a particular interpretation of the data. In this example, the solution with the default initial kernel parameters corresponds to a low frequency signal with high noise whereas the second solution with custom initial kernel parameters corresponds to a high frequency signal with low noise.
Load the sample data.
load('gprdata.mat')There are six continuous predictor variables. There are 500 observations in the training data set and 100 observations in the test data set. This is simulated data.
Fit a GPR model using the squared exponential kernel function with a separate length scale for each predictor. This covariance function is defined as:
where represents the length scale for predictor , = 1, 2, ..., and is the signal standard deviation. The unconstrained parametrization is
Initialize length scales of the kernel function at 10 and signal and noise standard deviations at the standard deviation of the response.
sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(Xtrain,2); sigmaM0 = 10*ones(d,1);
Fit the GPR model using the initial kernel parameter values. Standardize the predictors in the training data. Use the exact fitting and prediction methods.
gprMdl = fitrgp(Xtrain,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
Compute the regression loss on the test data.
L = loss(gprMdl,Xtest,ytest)
L = 0.6919
Access the kernel information.
gprMdl.KernelInformation
ans = struct with fields:
Name: 'ARDSquaredExponential'
KernelParameters: [7×1 double]
KernelParameterNames: {7×1 cell}
Display the kernel parameter names. When you use an ARD kernel, the length scale parameters correspond to the expanded predictors. Replace the length scale parameter names with the expanded predictor names.
paramNames = gprMdl.KernelInformation.KernelParameterNames
paramNames = 7×1 cell
{'LengthScale1'}
{'LengthScale2'}
{'LengthScale3'}
{'LengthScale4'}
{'LengthScale5'}
{'LengthScale6'}
{'SigmaF' }
paramNames(1:end-1) = gprMdl.ExpandedPredictorNames
paramNames = 7×1 cell
{'x1' }
{'x2' }
{'x3' }
{'x4' }
{'x5' }
{'x6' }
{'SigmaF'}
Display the kernel parameters.
sigmaM = gprMdl.KernelInformation.KernelParameters(1:end-1,1)
sigmaM = 6×1
104 ×
0.0004
0.0007
0.0004
4.7605
0.1018
0.0056
sigmaF = gprMdl.KernelInformation.KernelParameters(end)
sigmaF = 28.1720
sigma = gprMdl.Sigma
sigma = 0.8162
Plot the log of learned length scales.
figure() plot((1:d)',log(sigmaM),'ro-'); xlabel('Length scale number'); ylabel('Log of length scale');
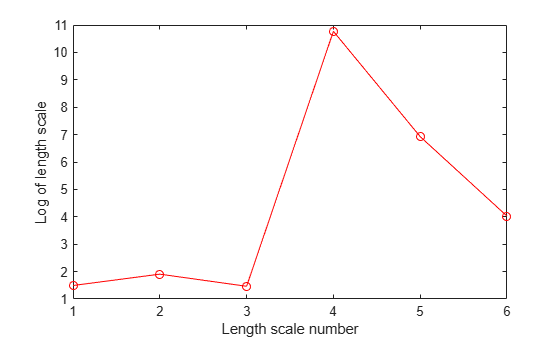
The log of length scale for the 4th and 5th predictor variables are high relative to the others. These predictor variables do not seem to be as influential on the response as the other predictor variables.
Fit the GPR model without using the 4th and 5th variables as the predictor variables.
X = [Xtrain(:,1:3) Xtrain(:,6)]; sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(X,2); sigmaM0 = 10*ones(d,1); gprMdl = fitrgp(X,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
Compute the regression error on the test data.
xtest = [Xtest(:,1:3) Xtest(:,6)]; L = loss(gprMdl,xtest,ytest)
L = 0.6928
The loss is similar to the one when all variables are used as predictor variables.
Compute the predicted response for the test data.
ypred = predict(gprMdl,xtest);
Plot the original response along with the fitted values.
figure; plot(ytest,'r'); hold on; plot(ypred,'b'); legend('True response','GPR predicted values','Location','Best'); hold off
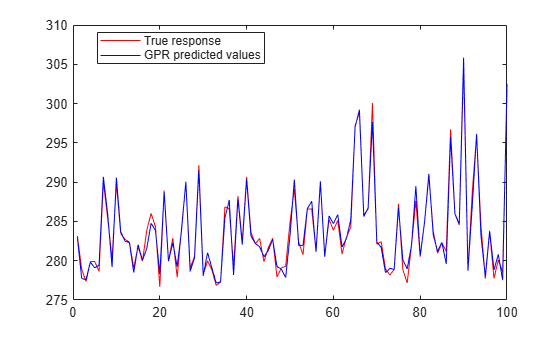
Automatically optimize hyperparameters of a GPR model using fitrgp. Compare the fit of the model with the optimized hyperparameter values to the fit of the model with the default hyperparameter values.
Load the gprdata2 data set.
load gprdata2The simulated data consists of one predictor variable and one continuous response.
Fit a GPR model using the squared exponential kernel function with default kernel parameters.
gprMdl1 = fitrgp(x,y,KernelFunction="squaredexponential");Find hyperparameters that minimize the 5-fold cross-validation loss by using automatic hyperparameter optimization. For reproducibility, set the random seed and use the "expected-improvement-plus" acquisition function.
rng(0,"twister") hpoOptions = hyperparameterOptimizationOptions(AcquisitionFunctionName="expected-improvement-plus"); gprMdl2 = fitrgp(x,y,KernelFunction="squaredexponential", ... OptimizeHyperparameters="auto",HyperparameterOptimizationOptions=hpoOptions);
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | Standardize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 1 | Best | 0.42258 | 0.98455 | 0.42258 | 0.42258 | 2.7255 | false |
| 2 | Accept | 1.1091 | 1.2998 | 0.42258 | 0.61465 | 0.0057724 | true |
| 3 | Accept | 1.6498 | 0.63221 | 0.42258 | 0.75989 | 25.905 | true |
| 4 | Best | 0.29824 | 1.0615 | 0.29824 | 0.29834 | 0.0098001 | false |
| 5 | Accept | 1.0387 | 1.3048 | 0.29824 | 0.49293 | 0.00010004 | false |
| 6 | Best | 0.037911 | 1.0524 | 0.037911 | 0.038158 | 0.13791 | false |
| 7 | Accept | 0.042394 | 0.86498 | 0.037911 | 0.038142 | 0.079273 | false |
| 8 | Accept | 0.038899 | 1.1123 | 0.037911 | 0.037126 | 0.11545 | false |
| 9 | Accept | 0.038969 | 0.97929 | 0.037911 | 0.037592 | 0.11307 | false |
| 10 | Accept | 0.039193 | 0.92651 | 0.037911 | 0.037928 | 0.1124 | false |
| 11 | Accept | 1.1496 | 1.1498 | 0.037911 | 0.03793 | 0.0001 | true |
| 12 | Accept | 0.13152 | 0.87078 | 0.037911 | 0.038375 | 0.37155 | true |
| 13 | Accept | 0.037915 | 0.87061 | 0.037911 | 0.038351 | 0.13701 | true |
| 14 | Best | 0.037785 | 0.87043 | 0.037785 | 0.038272 | 0.18141 | true |
| 15 | Best | 0.037697 | 0.8999 | 0.037697 | 0.03876 | 0.32603 | false |
| 16 | Accept | 0.037716 | 1.5285 | 0.037697 | 0.038783 | 0.22469 | false |
| 17 | Accept | 0.037832 | 1.0669 | 0.037697 | 0.036007 | 0.16182 | true |
| 18 | Accept | 0.037702 | 0.90477 | 0.037697 | 0.036011 | 0.23962 | false |
| 19 | Accept | 0.037838 | 1.2147 | 0.037697 | 0.036467 | 0.15992 | true |
| 20 | Best | 0.037694 | 0.92677 | 0.037694 | 0.036469 | 0.24919 | false |
|=====================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | Standardize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | |
|=====================================================================================================|
| 21 | Accept | 0.037841 | 1.0112 | 0.037694 | 0.03675 | 0.15878 | true |
| 22 | Accept | 0.037765 | 1.005 | 0.037694 | 0.036751 | 0.19128 | false |
| 23 | Best | 0.037683 | 0.92424 | 0.037683 | 0.036752 | 0.27578 | false |
| 24 | Accept | 2.1082 | 0.77623 | 0.037683 | 0.036754 | 29.263 | false |
| 25 | Accept | 0.42164 | 0.67778 | 0.037683 | 0.034063 | 0.5675 | false |
| 26 | Accept | 0.29404 | 0.90962 | 0.037683 | 0.034072 | 0.029617 | false |
| 27 | Accept | 1.0384 | 0.86692 | 0.037683 | 0.034106 | 0.0021049 | false |
| 28 | Accept | 0.28288 | 1.0758 | 0.037683 | 0.034043 | 0.051917 | true |
| 29 | Accept | 0.42298 | 0.79032 | 0.037683 | 0.03404 | 1.3844 | true |
| 30 | Accept | 0.29873 | 1.2886 | 0.037683 | 0.034238 | 0.00073587 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 44.8443 seconds
Total objective function evaluation time: 29.8472
Best observed feasible point:
Sigma Standardize
_______ ___________
0.27578 false
Observed objective function value = 0.037683
Estimated objective function value = 0.034238
Function evaluation time = 0.92424
Best estimated feasible point (according to models):
Sigma Standardize
_______ ___________
0.27578 false
Estimated objective function value = 0.034238
Estimated function evaluation time = 0.95655
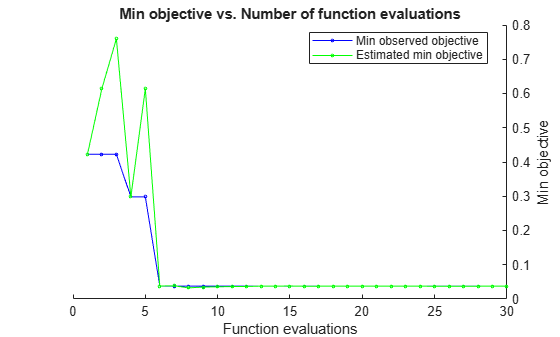
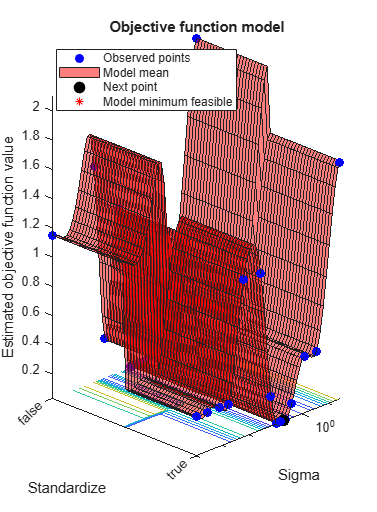
The trained regression model gprMdl2 corresponds to the best estimated feasible point and uses the same hyperparameter values for Sigma and Standardize.
Find the hyperparameter values used to train gprMdl2 by using the bestPoint function. By default, bestPoint uses the same best point criterion used by fitrgp during the hyperparameter optimization ("min-visited-upper-confidence-interval"). In general, fit functions determine the best hyperparameter values based on the "min-visited-upper-confidence-interval" criterion (instead of the "min-observed" criterion) to avoid overfitting to noise in the data set.
bestEstimatedPoint = bestPoint(gprMdl2.HyperparameterOptimizationResults)
bestEstimatedPoint=1×2 table
Sigma Standardize
_______ ___________
0.27578 false
Verify that the results match the properties of gprMdl2. Note that the PredictorLocation and PredictorScale properties of a RegressionGP object are nonempty when the GPR model uses standardization.
modelProperties = table(gprMdl2.Sigma, ... struct(Mean=gprMdl2.PredictorLocation, ... StandardDeviation=gprMdl2.PredictorScale), ... VariableNames=["Sigma","Standardize"])
modelProperties=1×2 table
Sigma Standardize
_______ ___________
0.27578 1×1 struct
modelProperties.Standardize
ans = struct with fields:
Mean: []
StandardDeviation: []
Visually compare the pre- and post-optimization fits.
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2); figure plot(x,y,".") hold on plot(x,ypred1) plot(x,ypred2) xlabel("x"); ylabel("y"); legend(["Data","Default fit","Optimized fit"], ... Location="best") title("Impact of Optimization") hold off
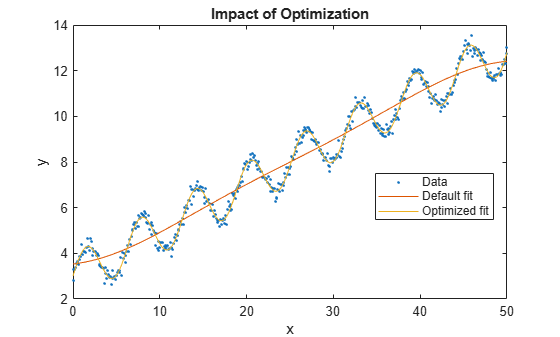
The model with the optimized hyperparameters provides a better fit to the training data.
This example uses the abalone data [1], [2], from the UCI Machine Learning Repository [3]. Download the data and save it in your current folder with the name abalone.data.
Store the data into a table. Display the first seven rows.
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height','WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20The dataset has 4177 observations. The goal is to predict the age of abalone from eight physical measurements. The last variable, number of shell rings shows the age of the abalone. The first predictor is a categorical variable. The last variable in the table is the response variable.
Train a cross-validated GPR model using the 25% of the data for validation.
rng('default') % For reproducibility cvgprMdl = fitrgp(tbl,'NoShellRings','Standardize',1,'Holdout',0.25);
Compute the average loss on folds using models trained on out-of-fold observations.
kfoldLoss(cvgprMdl)
ans = 4.6409
Predict the responses for out-of-fold data.
ypred = kfoldPredict(cvgprMdl);
Plot the true responses used for testing and the predictions.
figure(); plot(ypred(cvgprMdl.Partition.test)); hold on; y = table2array(tbl(:,end)); plot(y(cvgprMdl.Partition.test),'r.'); axis([0 1050 0 30]); xlabel('x') ylabel('y') hold off;
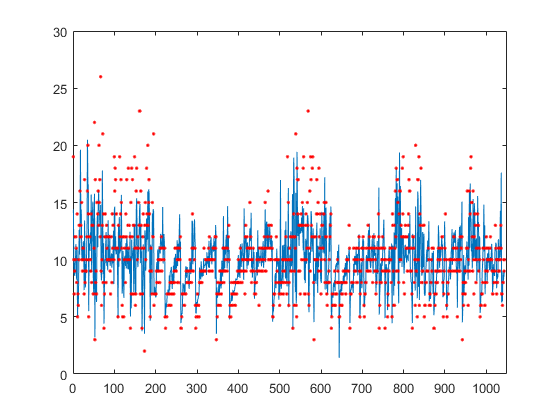
Generate the sample data.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Define the squared exponential kernel function as a custom kernel function.
You can compute the squared exponential kernel function as
where is the signal standard deviation, is the length scale. Both and must be greater than zero. This condition can be enforced by the unconstrained parameterization, and , for some unconstrained parameterization vector .
Hence, you can define the squared exponential kernel function as a custom kernel function as follows:
kfcn = @(XN,XM,theta) (exp(theta(2))^2)*exp(-(pdist2(XN,XM).^2)/(2*exp(theta(1))^2));
Here pdist2(XN,XM).^2 computes the distance matrix.
Fit a GPR model using the custom kernel function, kfcn. Specify the initial values of the kernel parameters (Because you use a custom kernel function, you must provide initial values for the unconstrained parameterization vector, theta).
theta0 = [1.5,0.2]; gprMdl = fitrgp(x,y,'KernelFunction',kfcn,'KernelParameters',theta0);
fitrgp uses analytical derivatives to estimate parameters when using a built-in kernel function, whereas when using a custom kernel function it uses numerical derivatives.
Compute the resubstitution loss for this model.
L = resubLoss(gprMdl)
L = 0.0391
Fit the GPR model using the built-in squared exponential kernel function option. Specify the initial values of the kernel parameters (Because you use the built-in custom kernel function and specifying initial parameter values, you must provide the initial values for the signal standard deviation and length scale(s) directly).
sigmaL0 = exp(1.5); sigmaF0 = exp(0.2); gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential','KernelParameters',[sigmaL0,sigmaF0]);
Compute the resubstitution loss for this model.
L2 = resubLoss(gprMdl2)
L2 = 0.0391
The two loss values are the same as expected.
Train a GPR model on generated data with many predictors. Specify the initial step size for the LBFGS optimizer.
Set the seed and type of the random number generator for reproducibility of the results.
rng(0,'twister'); % For reproducibility
Generate sample data with 300 observations and 3000 predictors, where the response variable depends on the 4th, 7th, and 13th predictors.
N = 300; P = 3000; X = rand(N,P); y = cos(X(:,7)) + sin(X(:,4).*X(:,13)) + 0.1*randn(N,1);
Set initial values for the kernel parameters.
sigmaL0 = sqrt(P)*ones(P,1); % Length scale for predictors sigmaF0 = 1; % Signal standard deviation
Set initial noise standard deviation to 1.
sigmaN0 = 1;
Specify 1e-2 as the termination tolerance for the relative gradient norm.
opts = statset('fitrgp');
opts.TolFun = 1e-2;Fit a GPR model using the initial kernel parameter values, initial noise standard deviation, and an automatic relevance determination (ARD) squared exponential kernel function.
Specify the initial step size as 1 for determining the initial Hessian approximation for an LBFGS optimizer.
gpr = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Verbose',1, ... 'Optimizer','lbfgs','OptimizerOptions',opts, ... 'KernelParameters',[sigmaL0;sigmaF0],'Sigma',sigmaN0,'InitialStepSize',1);
o Parameter estimation: FitMethod = Exact, Optimizer = lbfgs
o Solver = LBFGS, HessianHistorySize = 15, LineSearchMethod = weakwolfe
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 0 | 3.004966e+02 | 2.569e+02 | 0.000e+00 | | 3.893e-03 | 0.000e+00 | YES |
| 1 | 9.525779e+01 | 1.281e+02 | 1.003e+00 | OK | 6.913e-03 | 1.000e+00 | YES |
| 2 | 3.972026e+01 | 1.647e+01 | 7.639e-01 | OK | 4.718e-03 | 5.000e-01 | YES |
| 3 | 3.893873e+01 | 1.073e+01 | 1.057e-01 | OK | 3.243e-03 | 1.000e+00 | YES |
| 4 | 3.859904e+01 | 5.659e+00 | 3.282e-02 | OK | 3.346e-03 | 1.000e+00 | YES |
| 5 | 3.748912e+01 | 1.030e+01 | 1.395e-01 | OK | 1.460e-03 | 1.000e+00 | YES |
| 6 | 2.028104e+01 | 1.380e+02 | 2.010e+00 | OK | 2.326e-03 | 1.000e+00 | YES |
| 7 | 2.001849e+01 | 1.510e+01 | 9.685e-01 | OK | 2.344e-03 | 1.000e+00 | YES |
| 8 | -7.706109e+00 | 8.340e+01 | 1.125e+00 | OK | 5.771e-04 | 1.000e+00 | YES |
| 9 | -1.786074e+01 | 2.323e+02 | 2.647e+00 | OK | 4.217e-03 | 1.250e-01 | YES |
| 10 | -4.058422e+01 | 1.972e+02 | 6.796e-01 | OK | 7.035e-03 | 1.000e+00 | YES |
| 11 | -7.850209e+01 | 4.432e+01 | 8.335e-01 | OK | 3.099e-03 | 1.000e+00 | YES |
| 12 | -1.312162e+02 | 3.334e+01 | 1.277e+00 | OK | 5.432e-02 | 1.000e+00 | YES |
| 13 | -2.005064e+02 | 9.519e+01 | 2.828e+00 | OK | 5.292e-03 | 1.000e+00 | YES |
| 14 | -2.070150e+02 | 1.898e+01 | 1.641e+00 | OK | 6.817e-03 | 1.000e+00 | YES |
| 15 | -2.108086e+02 | 3.793e+01 | 7.685e-01 | OK | 3.479e-03 | 1.000e+00 | YES |
| 16 | -2.122920e+02 | 7.057e+00 | 1.591e-01 | OK | 2.055e-03 | 1.000e+00 | YES |
| 17 | -2.125610e+02 | 4.337e+00 | 4.818e-02 | OK | 1.974e-03 | 1.000e+00 | YES |
| 18 | -2.130162e+02 | 1.178e+01 | 8.891e-02 | OK | 2.856e-03 | 1.000e+00 | YES |
| 19 | -2.139378e+02 | 1.933e+01 | 2.371e-01 | OK | 1.029e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 20 | -2.151111e+02 | 1.550e+01 | 3.015e-01 | OK | 2.765e-02 | 1.000e+00 | YES |
| 21 | -2.173046e+02 | 5.856e+00 | 6.537e-01 | OK | 1.414e-02 | 1.000e+00 | YES |
| 22 | -2.201781e+02 | 8.918e+00 | 8.484e-01 | OK | 6.381e-03 | 1.000e+00 | YES |
| 23 | -2.288858e+02 | 4.846e+01 | 2.311e+00 | OK | 2.661e-03 | 1.000e+00 | YES |
| 24 | -2.392171e+02 | 1.190e+02 | 6.283e+00 | OK | 8.113e-03 | 1.000e+00 | YES |
| 25 | -2.511145e+02 | 1.008e+02 | 1.198e+00 | OK | 1.605e-02 | 1.000e+00 | YES |
| 26 | -2.742547e+02 | 2.207e+01 | 1.231e+00 | OK | 3.191e-03 | 1.000e+00 | YES |
| 27 | -2.849931e+02 | 5.067e+01 | 3.660e+00 | OK | 5.184e-03 | 1.000e+00 | YES |
| 28 | -2.899797e+02 | 2.068e+01 | 1.162e+00 | OK | 6.270e-03 | 1.000e+00 | YES |
| 29 | -2.916723e+02 | 1.816e+01 | 3.213e-01 | OK | 1.415e-02 | 1.000e+00 | YES |
| 30 | -2.947674e+02 | 6.965e+00 | 1.126e+00 | OK | 6.339e-03 | 1.000e+00 | YES |
| 31 | -2.962491e+02 | 1.349e+01 | 2.352e-01 | OK | 8.999e-03 | 1.000e+00 | YES |
| 32 | -3.004921e+02 | 1.586e+01 | 9.880e-01 | OK | 3.940e-02 | 1.000e+00 | YES |
| 33 | -3.118906e+02 | 1.889e+01 | 3.318e+00 | OK | 1.213e-01 | 1.000e+00 | YES |
| 34 | -3.189215e+02 | 7.086e+01 | 3.070e+00 | OK | 8.095e-03 | 1.000e+00 | YES |
| 35 | -3.245557e+02 | 4.366e+00 | 1.397e+00 | OK | 2.718e-03 | 1.000e+00 | YES |
| 36 | -3.254613e+02 | 3.751e+00 | 6.546e-01 | OK | 1.004e-02 | 1.000e+00 | YES |
| 37 | -3.262823e+02 | 4.011e+00 | 2.026e-01 | OK | 2.441e-02 | 1.000e+00 | YES |
| 38 | -3.325606e+02 | 1.773e+01 | 2.427e+00 | OK | 5.234e-02 | 1.000e+00 | YES |
| 39 | -3.350374e+02 | 1.201e+01 | 1.603e+00 | OK | 2.674e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 40 | -3.379112e+02 | 5.280e+00 | 1.393e+00 | OK | 1.177e-02 | 1.000e+00 | YES |
| 41 | -3.389136e+02 | 3.061e+00 | 7.121e-01 | OK | 2.935e-02 | 1.000e+00 | YES |
| 42 | -3.401070e+02 | 4.094e+00 | 6.224e-01 | OK | 3.399e-02 | 1.000e+00 | YES |
| 43 | -3.436291e+02 | 8.833e+00 | 1.707e+00 | OK | 5.231e-02 | 1.000e+00 | YES |
| 44 | -3.456295e+02 | 5.891e+00 | 1.424e+00 | OK | 3.772e-02 | 1.000e+00 | YES |
| 45 | -3.460069e+02 | 1.126e+01 | 2.580e+00 | OK | 3.907e-02 | 1.000e+00 | YES |
| 46 | -3.481756e+02 | 1.546e+00 | 8.142e-01 | OK | 1.565e-02 | 1.000e+00 | YES |
Infinity norm of the final gradient = 1.546e+00
Two norm of the final step = 8.142e-01, TolX = 1.000e-12
Relative infinity norm of the final gradient = 6.016e-03, TolFun = 1.000e-02
EXIT: Local minimum found.
o Alpha estimation: PredictMethod = Exact
Because the GPR model uses an ARD kernel with many predictors, using an LBFGS approximation to the Hessian is more memory efficient than storing the full Hessian matrix. Also, using the initial step size to determine the initial Hessian approximation may help speed up optimization.
Find the predictor weights by taking the exponential of the negative learned length scales. Normalize the weights.
sigmaL = gpr.KernelInformation.KernelParameters(1:end-1); % Learned length scales weights = exp(-sigmaL); % Predictor weights weights = weights/sum(weights); % Normalized predictor weights
Plot the normalized predictor weights.
figure; semilogx(weights,'ro'); xlabel('Predictor index'); ylabel('Predictor weight');
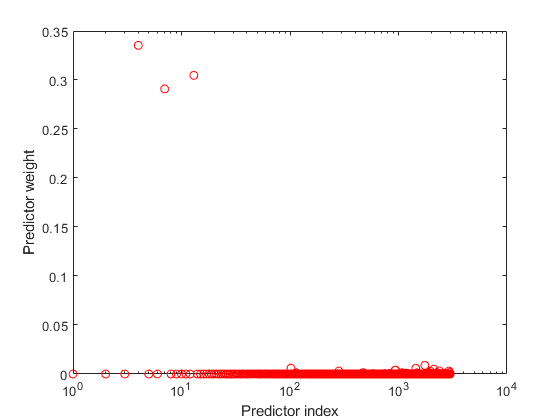
The trained GPR model assigns the largest weights to the 4th, 7th, and 13th predictors. The irrelevant predictors have weights close to zero.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
fitrgpaccepts any combination of fitting, prediction, and active set selection methods. In some cases it might not be possible to compute the standard deviations of the predicted responses, hence the prediction intervals. Seepredict. And in some cases, using the exact method might be expensive due to the size of the training data.The
PredictorNamesproperty stores one element for each of the original predictor variable names. For example, if there are three predictors, one of which is a categorical variable with three levels,PredictorNamesis a 1-by-3 cell array of character vectors.The
ExpandedPredictorNamesproperty stores one element for each of the predictor variables, including the dummy variables. For example, if there are three predictors, one of which is a categorical variable with three levels, thenExpandedPredictorNamesis a 1-by-5 cell array of character vectors.Similarly, the
Betaproperty stores one beta coefficient for each predictor, including the dummy variables.The
Xproperty stores the training data as originally input. It does not include the dummy variables.The default approach to initializing the Hessian approximation in
fitrgpcan be slow when you have a GPR model with many kernel parameters, such as when using an ARD kernel with many predictors. In this case, consider specifying"auto"or a value for the initial step size.You can set
Verbose=1for display of iterative diagnostic messages, and begin training a GPR model using an LBFGS or quasi-Newton optimizer with the defaultfitrgpoptimization. If the iterative diagnostic messages are not displayed after a few seconds, it is possible that initialization of the Hessian approximation is taking too long. In this case, consider restarting training and using the initial step size to speed up optimization.After training a model, you can generate C/C++ code that predicts responses for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions..
Algorithms
Fitting a GPR model involves estimating the following model parameters from the data:
Covariance function parameterized in terms of kernel parameters in vector (see Kernel (Covariance) Function Options)
Noise variance
Coefficient vector of fixed-basis functions
The value of the
KernelParametersname-value argument is a vector that consists of initial values for the signal standard deviation and the characteristic length scales . The software uses these values to determine the kernel parameters. Similarly, theSigmaname-value argument contains the initial value for the noise standard deviation .During optimization, the software creates a vector of unconstrained initial parameter values by using the initial values for the noise standard deviation and the kernel parameters.
The software analytically determines the explicit basis coefficients , specified by the
Betaname-value argument, from estimated values of and . Therefore, does not appear in the vector when the software initializes numerical optimization.Note
If you do not specify the estimation of parameters for the GPR model, the software uses the value of the
Betaname-value argument and other initial parameter values as the known GPR parameter values (seeBeta). In all other cases, the value ofBetais optimized analytically from the objective function.The quasi-Newton optimizer uses a trust-region method with a dense, symmetric rank-1-based (SR1), quasi-Newton approximation to the Hessian. The LBFGS optimizer uses a standard line-search method with a limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) quasi-Newton approximation to the Hessian. See Nocedal and Wright [6].
If you set the
InitialStepSizename-value argument to"auto"the software determines the initial step size by using .is the initial step vector, and is the vector of unconstrained initial parameter values.
During optimization, the software uses the initial step size as follows:
If you specify
Optimizer="quasinewton"with the initial step size, then the initial Hessian approximation is .If you specify
Optimizer="lbfgs"with the initial step size, then the initial inverse-Hessian approximation is .is the initial gradient vector, and is the identity matrix.
References
[1] Nash, W.J., T. L. Sellers, S. R. Talbot, A. J. Cawthorn, and W. B. Ford. "The Population Biology of Abalone (Haliotis species) in Tasmania. I. Blacklip Abalone (H. rubra) from the North Coast and Islands of Bass Strait." Sea Fisheries Division, Technical Report No. 48, 1994.
[2] Waugh, S. "Extending and Benchmarking Cascade-Correlation: Extensions to the Cascade-Correlation Architecture and Benchmarking of Feed-forward Supervised Artificial Neural Networks." University of Tasmania Department of Computer Science thesis, 1995.
[3] Lichman, M. UCI Machine Learning Repository, Irvine, CA: University of California, School of Information and Computer Science, 2013. http://archive.ics.uci.edu/ml.
[4] Rasmussen, C. E. and C. K. I. Williams. Gaussian Processes for Machine Learning. MIT Press. Cambridge, Massachusetts, 2006.
[5] Lagarias, J. C., J. A. Reeds, M. H. Wright, and P. E. Wright. "Convergence Properties of the Nelder-Mead Simplex Method in Low Dimensions." SIAM Journal of Optimization. Vol. 9, Number 1, 1998, pp. 112–147.
[6] Nocedal, J. and S. J. Wright. Numerical Optimization, Second Edition. Springer Series in Operations Research, Springer Verlag, 2006.