updateMetricsAndFit
Update performance metrics in naive Bayes incremental learning classification model given new data and train model
Description
Given streaming data, updateMetricsAndFit first evaluates the performance of a configured naive Bayes classification model for incremental learning (incrementalClassificationNaiveBayes object) by calling updateMetrics on incoming data. Then updateMetricsAndFit fits the model to that data by calling fit. In other words, updateMetricsAndFit performs prequential evaluation because it treats each incoming chunk of data as a test set, and tracks performance metrics measured cumulatively and over a specified window [1].
updateMetricsAndFit provides a simple way to update model performance metrics and train the model on each chunk of data. Alternatively, you can perform the operations separately by calling updateMetrics and then fit, which allows for more flexibility (for example, you can decide whether you need to train the model based on its performance on a chunk of data).
Mdl = updateMetricsAndFit(Mdl,X,Y)Mdl, which is the input naive Bayes classification model for incremental learning Mdl with the following modifications:
updateMetricsAndFitmeasures the model performance on the incoming predictor and response data,XandYrespectively. When the input model is warm (Mdl.IsWarmistrue),updateMetricsAndFitoverwrites previously computed metrics, stored in theMetricsproperty, with the new values. Otherwise,updateMetricsAndFitstoresNaNvalues inMetricsinstead.updateMetricsAndFitfits the modified model to the incoming data by updating the conditional posterior mean and standard deviation of each predictor variable, given the class, and stores the new estimates, among other configurations, in the output modelMdl.
Examples
Create a naive Bayes classification model for incremental learning by calling incrementalClassificationNaiveBayes and specifying a maximum of 5 expected classes in the data.
Mdl = incrementalClassificationNaiveBayes('MaxNumClasses',5)Mdl =
incrementalClassificationNaiveBayes
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
DistributionNames: 'normal'
DistributionParameters: {}
Properties, Methods
Mdl is an incrementalClassificationNaiveBayes model object. All its properties are read-only.
Mdl must be fit to data before you can use it to perform any other operations.
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Implement incremental learning by performing the following actions at each iteration:
Simulate a data stream by processing a chunk of 50 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store the conditional mean of the first predictor in the first class , the cumulative metrics, and the window metrics to see how they evolve during incremental learning.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); mc = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); mu11 = zeros(nchunk,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetricsAndFit(Mdl,X(idx,:),Y(idx)); mc{j,:} = Mdl.Metrics{"MinimalCost",:}; mu11(j + 1) = Mdl.DistributionParameters{1,1}(1); end
Now, Mdl is an incrementalClassificationNaiveBayes model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetricsAndFit checks the performance of the model on the incoming observations, and then fits the model to those observations.
To see how the performance metrics and evolve during training, plot them on separate tiles.
t = tiledlayout(2,1); nexttile plot(mu11) ylabel('\mu_{11}') xlim([0 nchunk]) nexttile h = plot(mc.Variables); xlim([0 nchunk]) ylabel('Minimal Cost') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.') legend(h,mc.Properties.VariableNames) xlabel(t,'Iteration')
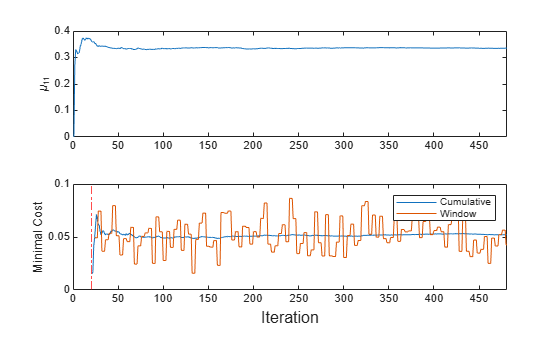
The plot indicates that updateMetricsAndFit performs the following actions:
Fit during all incremental learning iterations.
Compute the performance metrics after the metrics warm-up period only.
Compute the cumulative metrics during each iteration.
Compute the window metrics after processing 200 observations (4 iterations).
Train a naive Bayes classification model by using fitcnb, convert it to an incremental learner, track its performance on streaming data and fit it to the data in one call. Specify observation weights.
Load and Preprocess Data
Load the human activity data set. Randomly shuffle the data.
load humanactivity rng(1) % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Suppose that the data from a stationary subject (Y <= 2) has double the quality of data from a moving subject. Create a weight variable that assigns a weight of 2 to observations from a stationary subject and 1 to a moving subject.
W = ones(n,1) + (Y <= 2);
Train Naive Bayes Classification Model
Fit a naive Bayes classification model to a random sample of half the data.
idxtt = randsample([true false],n,true);
TTMdl = fitcnb(X(idxtt,:),Y(idxtt),'Weights',W(idxtt))TTMdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
NumObservations: 12053
DistributionNames: {1×60 cell}
DistributionParameters: {5×60 cell}
Properties, Methods
TTMdl is a ClassificationNaiveBayes model object representing a traditionally trained naive Bayes classification model.
Convert Trained Model
Convert the traditionally trained model to a naive Bayes classification model for incremental learning. Specify tracking the misclassification error rate during incremental learning.
IncrementalMdl = incrementalLearner(TTMdl,'Metrics',"classiferror")
IncrementalMdl =
incrementalClassificationNaiveBayes
IsWarm: 1
Metrics: [2×2 table]
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
DistributionNames: {1×60 cell}
DistributionParameters: {5×60 cell}
Properties, Methods
IncrementalMdl is an incrementalClassificationNaiveBayes model. Because class names are specified in IncrementalMdl.ClassNames, labels encountered during incremental learning must be in IncrementalMdl.ClassNames.
Track Performance Metrics and Fit Model
Perform incremental learning on the rest of the data by using the updateMetricsAndFit function. At each iteration:
Simulate a data stream by processing 50 observations at a time.
Call
updateMetricsAndFitto update the cumulative and window performance metrics of the model given the incoming chunk of observations, and then fit the model to the data. Overwrite the previous incremental model with a new one. Specify the observation weights.Store the misclassification error rate.
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); mc = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); Xil = X(idxil,:); Yil = Y(idxil); Wil = W(idxil); % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx),... 'Weights',Wil(idx)); mc{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; end
Now, IncrementalMdl is an incrementalClassificationNaiveBayes model object trained on all the data in the stream.
Create a trace plot of the misclassification error rate.
h = plot(mc.Variables); xlim([0 nchunk]) ylabel('Classification Error') legend(h,mc.Properties.VariableNames) xlabel('Iteration')
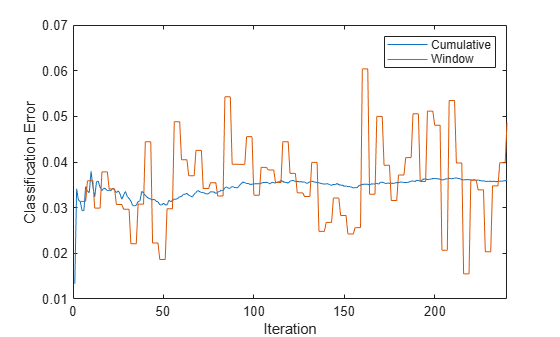
The cumulative loss initially jumps, but stabilizes around 0.05, whereas the window loss jumps throughout the training.