ttest
One-sample and paired-sample t-test
Syntax
Description
h = ttest(x)x comes
from a normal distribution with mean equal to zero and unknown variance,
using the one-sample t-test.
The alternative hypothesis is that the population distribution does
not have a mean equal to zero. The result h is 1 if
the test rejects the null hypothesis at the 5% significance level,
and 0 otherwise.
h = ttest(x,y)x –
y comes from a normal distribution with mean equal to zero and
unknown variance, using the paired-sample
t-test. The alternative hypothesis is that the
mean of the data in x – y is not equal to zero.
h = ttest(x,y,Name,Value)
h = ttest(x,m,Name,Value)
Examples
Load the sample data. Create a vector containing the third column of the stock returns data.
load stockreturns
x = stocks(:,3);Test the null hypothesis that the sample data comes from a population with mean equal to zero.
[h,p,ci,stats] = ttest(x)
h = 1
p = 0.0106
ci = 2×1
-0.7357
-0.0997
stats = struct with fields:
tstat: -2.6065
df: 99
sd: 1.6027
The returned value h = 1 indicates that ttest rejects the null hypothesis at the 5% significance level.
Load the sample data. Create a vector containing the third column of the stock returns data.
load stockreturns
x = stocks(:,3);Test the null hypothesis that the sample data are from a population with mean equal to zero at the 1% significance level.
h = ttest(x,0,'Alpha',0.01)h = 0
The returned value h = 0 indicates that ttest does not reject the null hypothesis at the 1% significance level.
Load the sample data. Create vectors containing the first and second columns of the data matrix to represent students’ grades on two exams.
load examgrades
x = grades(:,1);
y = grades(:,2);Test the null hypothesis that the pairwise difference between data vectors x and y has a mean equal to zero.
[h,p] = ttest(x,y)
h = 0
p = 0.9805
The returned value of h = 0 indicates that ttest does not reject the null hypothesis at the default 5% significance level.
Load the sample data. Create vectors containing the first and second columns of the data matrix to represent students’ grades on two exams.
load examgrades
x = grades(:,1);
y = grades(:,2);Test the null hypothesis that the pairwise difference between data vectors x and y has a mean equal to zero at the 1% significance level.
[h,p] = ttest(x,y,'Alpha',0.01)h = 0
p = 0.9805
The returned value of h = 0 indicates that ttest does not reject the null hypothesis at the 1% significance level.
Load the sample data. Create a vector containing the first column of the students' exam grades data.
load examgrades
x = grades(:,1);Test the null hypothesis that sample data comes from a distribution with mean m = 75.
h = ttest(x,75)
h = 0
The returned value of h = 0 indicates that ttest does not reject the null hypothesis at the 5% significance level.
Load the sample data. Create a vector containing the first column of the students’ exam grades data.
load examgrades
x = grades(:,1);Plot a histogram of the exam grades data and fit a normal density function.
histfit(x) xlabel("Grade") ylabel("Frequency")
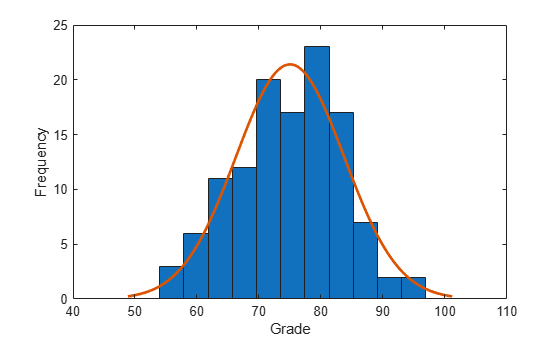
Use a right-tailed t-test to test the null hypothesis that the data comes from a population with mean equal to 65, against the alternative that the mean is greater than 65.
[h,~,~,stats] = ttest(x,65,"Tail","right")
h = 1
stats = struct with fields:
tstat: 12.5726
df: 119
sd: 8.7202
The returned value of h = 1 indicates that ttest rejects the null hypothesis at the default significance level of 5%, in favor of the alternative hypothesis that the data comes from a population with a mean greater than 65.
Plot the corresponding Student's t-distribution, the returned t-statistic, and the critical t-value. Calculate the critical t-value for the default confidence level of 95% by using tinv.
nu = stats.df; k = linspace(-15,15,300); tdistpdf = tpdf(k,nu); tval = stats.tstat
tval = 12.5726
tvalpdf = tpdf(tval,nu); tcrit = tinv(0.95,nu)
tcrit = 1.6578
plot(k,tdistpdf) hold on scatter(tval,tvalpdf,"filled") xline(tcrit,"--") legend(["Student's t pdf", "t-Statistic", ... "Critical Cutoff"])
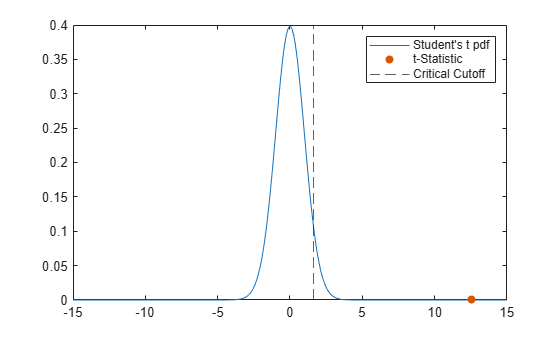
The orange dot represents the t-statistic and is located to the right of the dashed black line that represents the critical t-value.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Use
sampsizepwrto calculate:The sample size that corresponds to specified power and parameter values;
The power achieved for a particular sample size, given the true parameter value;
The parameter value detectable with the specified sample size and power.
Extended Capabilities
Version History
Introduced before R2006a
See Also
ztest | ttest2 | sampsizepwr