How much faster does a small GPT train on an Apple Silicon GPU?
Duncan Carlsmith, Department of Physics, University of Wisconsin-Madison
Introduction
My prior post nanoGPT Arithmetic Explorer: A small MATLAB GPT that groks integer addition, and my FEX submission nanoGPT Arithmetic Explorer present a small character-level GPT in MATLAB that learns integer addition, trained entirely on the CPU. That project raised for me a practical question for anyone who, like me, runs MATLAB on a Mac: MATLAB has no GPU support on Apple Silicon - gpuArray and the Deep Learning Toolbox training path require an NVIDIA CUDA GPU - yet every M-series Mac carries a capable GPU, arguably a built-in NVIDIA Spark equivalent, that sits idle while the model trains. APPLE GPUs have reduced precision, but that is perhaps not relevant, even valued, in GPT applications. To access the APPLE GPU requires indirect methods. My new Live Script Mac GPT GPU Benchmark Explorer explores the speed up for small models with a small, reproducible GPT benchmark for any Mac. The workload is the same small GPT learning addition, so each variant can be checked to actually learn - to grok perfect answers on held-out problems. The same model is trained three ways on the same machine: the original MATLAB engine on the CPU, PyTorch on the CPU, and PyTorch on the Metal GPU through Apple's MPS backend. Three points let the total speedup factor into a framework effect and a device effect. The nanoGPT model is flexible in size, allowing extrapolation to larger models not needed in the arithmetic application.
On my M1 Max, the result is about a 7.7x speedup per training step moving from the MATLAB workflow to PyTorch on the GPU, and it factors as roughly 3.7x from the framework times 2.1x from the device. Most of the gain is not the GPU: likely PyTorch's fused attention, tuned linear algebra, and lighter automatic differentiation account for the larger factor, and the Metal GPU roughly doubles it again. With a fixed model seed, the CPU and GPU loss curves agree to several decimals, and both grok to perfect accuracy, so this is the same computation, only faster - all in single precision, which is what neural-network training often uses anyway and what every Apple GPU provides.
The script also pits Apple's own MLX framework against PyTorch on the GPU. MLX has its own Metal kernels and edges, PyTorch only for the smallest models; PyTorch pulls ahead as the model grows. A size sweep shows the GPU advantage ranging from roughly two to six times across a wide range of model sizes. Caveats: a laptop throttles under sustained load, so a long run reads slower per step than a short, timed burst. Other factors may enter. I'm no expert in benchmarking practices.
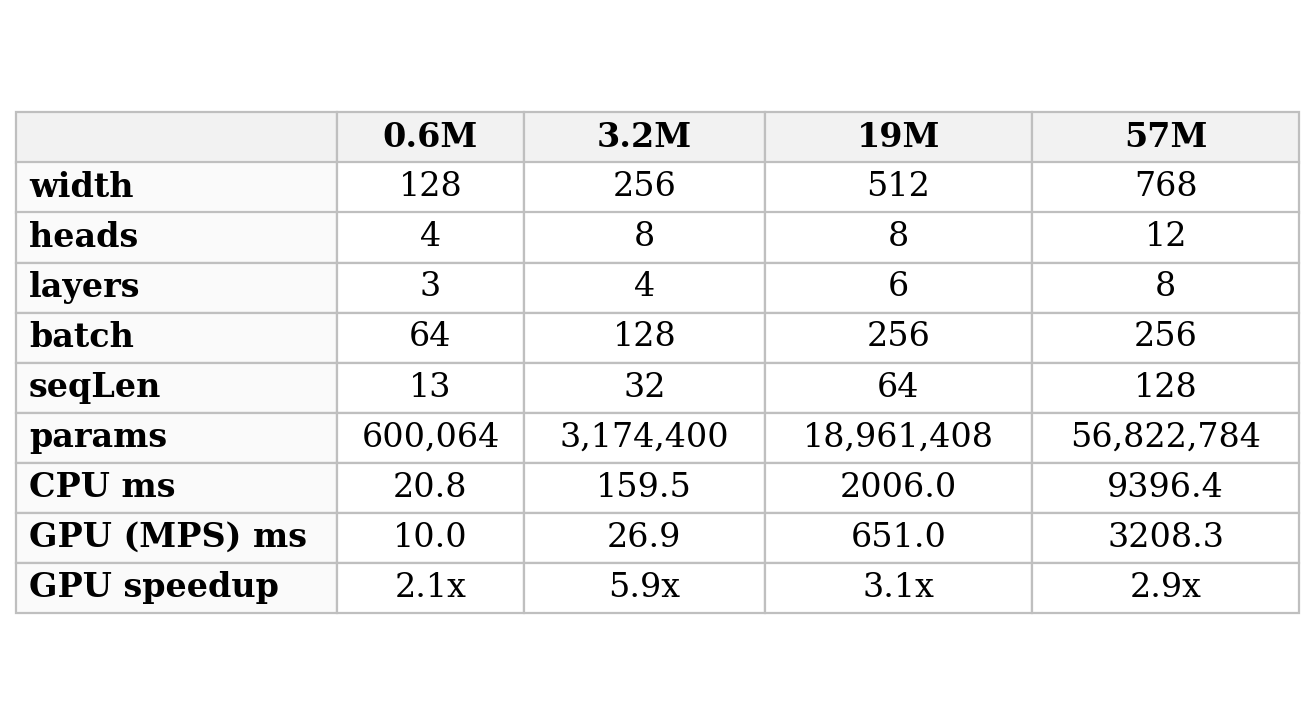
Table 1. The size sweep on the reference machine (Apple M1 Max): each column is one model configuration, headed by its parameter count, with the per-step training time on the CPU and on the Apple GPU (PyTorch-MPS). GPU speedup is CPU time divided by GPU time. It is a compound sweep - width, heads, layers, batch, and sequence length all change together.
 The Live Script is organized as three panels - the three-point comparison, the speedup-versus-size sweep, and the MLX-versus-PyTorch contrast. Each panel displays a precomputed result shipped with the package by default, and each has a "Try this" switch that regenerates it on your own Mac. A set of challenges suggests the reader extend the study, for example, with controlled single-variable sweeps or a run on a different Apple chip. The self-contained arithGPT trainer is bundled with the script; the GPU work runs in PyTorch and MLX, both free and open-source, with no paid API. The package and this writeup were built with Claude (Anthropic) working with MATLAB R2026a on my own MacBook with an M1 chip through an ngrok command server, the agentic context described in my prior posts.
The Live Script is organized as three panels - the three-point comparison, the speedup-versus-size sweep, and the MLX-versus-PyTorch contrast. Each panel displays a precomputed result shipped with the package by default, and each has a "Try this" switch that regenerates it on your own Mac. A set of challenges suggests the reader extend the study, for example, with controlled single-variable sweeps or a run on a different Apple chip. The self-contained arithGPT trainer is bundled with the script; the GPU work runs in PyTorch and MLX, both free and open-source, with no paid API. The package and this writeup were built with Claude (Anthropic) working with MATLAB R2026a on my own MacBook with an M1 chip through an ngrok command server, the agentic context described in my prior posts.A note on hardware: what "capable" means
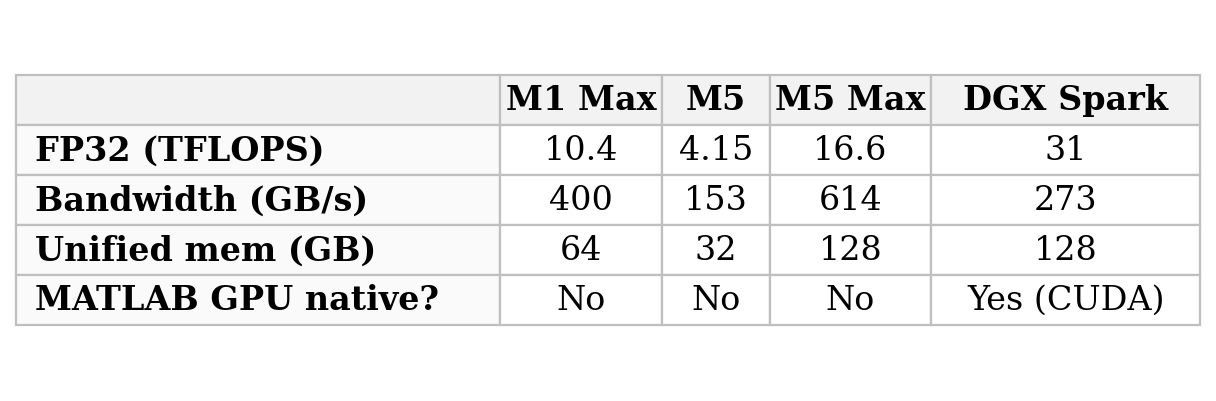
Three numbers describe a GPU for this kind of work. Compute is measured in TFLOPS - trillions of floating-point arithmetic operations per second - quoted at a stated numeric precision; FP32 means 32-bit floating-point numbers, the full-precision arithmetic this article trains in, and the standard for scientific computing. Memory bandwidth, in gigabytes per second (GB/s), is how fast the chip moves data between memory and its arithmetic units; for the small models trained here, that is often the real limit, rather than raw compute. Unified memory, in gigabytes (GB), is the single pool of memory that the CPU and GPU share on these chips, which sets how large a model can be held at once. The last row of the table is simply whether MATLAB's own GPU functions (gpuArray, trainnet) run on the machine: they require NVIDIA's CUDA platform, which no Apple Silicon Mac provides.
Table 2. GPU capability of the M1 Max used in this study, Apple's current M5 and M5 Max, and NVIDIA's DGX Spark, all at FP32 precision. Higher TFLOPS and bandwidth are faster; unified memory sets the largest model that fits; the last row is whether MATLAB's built-in GPU training runs on the machine.
The M1 Max used here delivers about 10 TFLOPS of FP32 at 400 GB/s - genuinely capable, and in fact more memory bandwidth than the brand-new DGX Spark. Apple's current line runs from the small M5 (4.15 TFLOPS, lower than the older M1 Max because it is the entry-level chip) up to the M5 Max (16.6 TFLOPS, 614 GB/s, 128 GB), the true successor that beats the M1 Max on every count.
The DGX Spark plays a different game. Its FP32 figure of about 31 TFLOPS is only part of the story; its real strength is arithmetic at very low precision, which Apple's GPUs do not offer. NVIDIA's headline 'one petaFLOP' (a thousand TFLOPS) is an FP4 number - 4-bit floating-point, sixteen times coarser than FP32 - and it also counts sparsity, a hardware trick that skips multiplications by zero; without that trick, it is about half as much. Four-bit numbers are far too coarse to train with, but they are precise enough to run an already-trained very large model, which is what the Spark is built for: large-model use on the desktop, not the full-precision training measured here. The detail that matters for this article is the last table row - because the Spark runs CUDA on Linux, MATLAB's own GPU training path works on it directly, the very thing that does not exist on any Mac, and the reason this study reached for PyTorch and MLX.
References
Acknowledgements
This submission and the FEX submission build and test were made with the assistance of Anthropic Claude in a few hours. The author has relied heavily on Claude's expertise. Caveat emptor.
Conflict of interest
The author declares he has no financial interest in MathWorks, Anthropic, or Apple. This article is informational and does not constitute an endorsement by the University of Wisconsin-Madison of any vendor or product. Claude is a trademark of Anthropic. MATLAB is a trademark of MathWorks. PyTorch, MLX, and Metal are trademarks of their respective owners.