isInNetworkDistribution
Syntax
Description
Add-On Required: This feature requires the AI Verification Library for Deep Learning Toolbox add-on.
tf = isInNetworkDistribution(net,X)X are
in-distribution (ID) and which observations are out-of-distribution (OOD). If an
observation is ID, then the corresponding element of tf is
1 (true). Otherwise, the corresponding element of
tf is 0 (false).
The function computes the distribution confidence score for each observation using the baseline method. For more information, see Softmax-Based Methods. The function classifies any observation with a score less than or equal to the threshold as OOD. To use the default threshold value, use this syntax.
To set the threshold, use the thr name-value
argument. Alternatively, use the networkDistributionDiscriminator function to create a discriminator object
that automatically finds an optimal threshold and use that as the first input argument
instead of net. You can also use the discriminator object to specify
a different method to use to compute the distribution confidence scores.
tf = isInNetworkDistribution(discriminator,X)X are ID and which observations are
OOD using discriminator. To create a discriminator object, use the
networkDistributionDiscriminator function. This syntax uses the threshold
stored in the Threshold property of
discriminator. Use this syntax to specify additional options for
the software to use when it computes the distribution confidence scores and to
automatically find a suitable threshold. For example, when creating a discriminator, you
can specify whether to use a target true positive or false positive rate to pick the
threshold. For more information, see networkDistributionDiscriminator.
tf = isInNetworkDistribution(discriminator,X1,...,XN)
tf = isInNetworkDistribution(___,Name=Value)Threshold and
VerbosityLevel options using one or more name-value arguments in addition to
the input arguments in previous syntaxes.
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
OOD data detection is a technique for assessing whether the inputs to a network are OOD. For methods that you apply after training, you can construct a discriminator which acts as an additional output of the trained network that classifies an observation as ID or OOD.
The discriminator works by finding a distribution confidence score for an input. You can then specify a threshold. If the score is less than or equal to that threshold, then the input is OOD. Two groups of metrics for computing distribution confidence scores are softmax-based and density-based methods. Softmax-based methods use the softmax layer to compute the scores. Density-based methods use the outputs of layers that you specify to compute the scores. For more information about how to compute distribution confidence scores, see Distribution Confidence Scores.
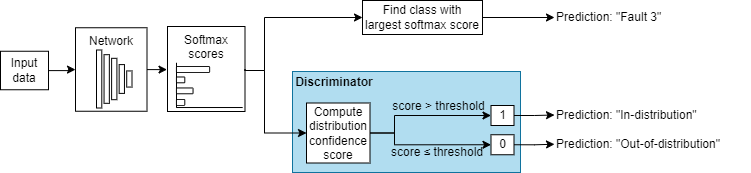
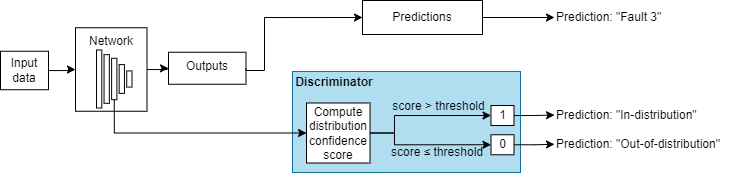
These images show how a discriminator acts as an additional output of a trained neural network.
Example Data Discriminators
| Example of Softmax-Based Discriminator | Example of Density-Based Discriminator |
|---|---|
|
For more information, see Softmax-Based Methods. |
For more information, see Density-Based Methods. |
References
[5] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu, “Generalized Out-of-Distribution Detection: A Survey” August 3, 2022, http://arxiv.org/abs/2110.11334.
[6] Lee, Kimin, Kibok Lee, Honglak Lee, and Jinwoo Shin. “A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks.” arXiv, October 27, 2018. http://arxiv.org/abs/1807.03888.