Define Text Decoder Model Function
This example shows how to define a text decoder model function.
In the context of deep learning, a decoder is the part of a deep learning network that maps a latent vector to some sample space. You can use decode the vectors for various tasks. For example,
Text generation by initializing a recurrent network with the encoded vector.
Sequence-to-sequence translation by using the encoded vector as a context vector.
Image captioning by using the encoded vector as a context vector.
Load Data
Load the encoded data from sonnetsEncoded.mat. This MAT file contains the word encoding, a mini-batch of sequences X, and the corresponding encoded data Z output by the encoder used in the example Define Text Encoder Model Function.
s = load("sonnetsEncoded.mat");
enc = s.enc;
X = s.X;
Z = s.Z;
[latentDimension,miniBatchSize] = size(Z,1:2);Initialize Model Parameters
The goal of the decoder is to generate sequences given some initial input data and network state.
Initialize the parameters for the following model.
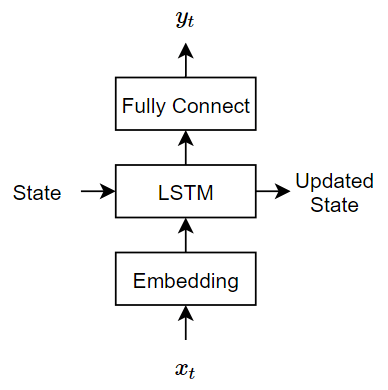
The decoder reconstructs the input using an LSTM initialized the encoder output. For each time step, the decoder predicts the next time step and uses the output for the next time-step predictions. Both the encoder and the decoder use the same embedding.
This model uses three operations:
The embedding maps word indices in the range 1 though
vocabularySizeto vectors of dimensionembeddingDimension, wherevocabularySizeis the number of words in the encoding vocabulary andembeddingDimensionis the number of components learned by the embedding.The LSTM operation takes as input a single word vector and outputs 1-by-
numHiddenUnitsvector, wherenumHiddenUnitsis the number of hidden units in the LSTM operation. The initial state of the LSTM network (the state at the first time-step) is the encoded vector, so the number of hidden units must match the latent dimension of the encoder.The fully connected operation multiplies the input by a weight matrix adding bias and outputs vectors of size
vocabularySize.
Specify the dimensions of the parameters. The embedding sizes must match the encoder.
embeddingDimension = 100; vocabularySize = enc.NumWords; numHiddenUnits = latentDimension;
Create a struct for the parameters.
parameters = struct;
Initialize the weights of the embedding using the Gaussian using the initializeGaussian function which is attached to this example as a supporting file. Specify a mean of 0 and a standard deviation of 0.01. To learn more, see Gaussian Initialization.
sz = [embeddingDimension vocabularySize]; mu = 0; sigma = 0.01; parameters.emb.Weights = initializeGaussian(sz,mu,sigma);
Initialize the learnable parameters for the decoder LSTM operation:
Initialize the input weights with the Glorot initializer using the
initializeGlorotfunction which is attached to this example as a supporting file. To learn more, see Glorot Initialization.Initialize the recurrent weights with the orthogonal initializer using the
initializeOrthogonalfunction which is attached to this example as a supporting file. To learn more, see Orthogonal Initialization.Initialize the bias with the unit forget gate initializer using the
initializeUnitForgetGatefunction which is attached to this example as a supporting file. To learn more, see Unit Forget Gate Initialization.
The sizes of the learnable parameters depend on the size of the input. Because the inputs to the LSTM operation are sequences of word vectors from the embedding operation, the number of input channels is embeddingDimension.
The input weight matrix has size
4*numHiddenUnits-by-inputSize, whereinputSizeis the dimension of the input data.The recurrent weight matrix has size
4*numHiddenUnits-by-numHiddenUnits.The bias vector has size
4*numHiddenUnits-by-1.
sz = [4*numHiddenUnits embeddingDimension]; numOut = 4*numHiddenUnits; numIn = embeddingDimension; parameters.lstmDecoder.InputWeights = initializeGlorot(sz,numOut,numIn); parameters.lstmDecoder.RecurrentWeights = initializeOrthogonal([4*numHiddenUnits numHiddenUnits]); parameters.lstmDecoder.Bias = initializeUnitForgetGate(numHiddenUnits);
Initialize the learnable parameters for the encoder fully connected operation:
Initialize the weights with the Glorot initializer.
Initialize the bias with zeros using the
initializeZerosfunction which is attached to this example as a supporting file. To learn more, see Zeros Initialization.
The sizes of the learnable parameters depend on the size of the input. Because the inputs to the fully connected operation are the outputs of the LSTM operation, the number of input channels is numHiddenUnits. To make the fully connected operation output vectors with size latentDimension, specify an output size of latentDimension.
The weights matrix has size
outputSize-by-inputSize, whereoutputSizeandinputSizecorrespond to the output and input dimensions, respectively.The bias vector has size
outputSize-by-1.
To make the fully connected operation output vectors with size vocabularySize, specify an output size of vocabularySize.
sz = [vocabularySize numHiddenUnits]; mu = 0; sigma = 1; parameters.fcDecoder.Weights = initializeGaussian(sz,mu,sigma); parameters.fcDecoder.Bias = initializeZeros([vocabularySize 1]);
Define Model Decoder Function
Create the function modelDecoder, listed in the Decoder Model Function section of the example, that computes the output of the decoder model. The modelDecoder function, takes as input sequences of word indices, the model parameters, and the sequence lengths, and returns the corresponding latent feature vector.
Use Model Function in Model Loss Function
When training a deep learning model with a custom training loop, you must calculate the loss and gradients of the loss with respect to the learnable parameters. This calculation depends on the output of a forward pass of the model function.
There are two common approaches to generating text data with a decoder:
Closed loop — For each time step, make predictions using the previous prediction as input.
Open loop — For each time step, make predictions using inputs from an external source (for example, training targets).
Closed Loop Generation
Closed loop generation is when the model generates data one time-step at a time and uses the previous prediction as input for the next prediction. Unlike open loop generation, this process does not require any input between predictions and is best suited for scenarios without supervision. For example, a language translation model that generates output text in one go.
Initialize the hidden state of the LSTM network with the encoder output Z.
state = struct;
state.HiddenState = Z;
state.CellState = zeros(size(Z),'like',Z);For the first time step, use an array of start tokens as input for the decoder. For simplicity, extract an array of start tokens from the first time-step of the training data.
decoderInput = X(:,:,1);
Preallocate the decoder output to have size numClasses-by-miniBatchSize-by-sequenceLength with the same datatype as dlX, where sequenceLength is the desired length of the generation, for example, the length of the training targets. For this example, specify a sequence length of 16.
sequenceLength = 16; Y = zeros(vocabularySize,miniBatchSize,sequenceLength,"like",X); Y = dlarray(Y,"CBT");
For each time step, predict the next time step of the sequence using the modelDecoder function. After each prediction, find the indices corresponding to the maximum values of the decoder output and use these indices as the decoder input for the next time step.
for t = 1:sequenceLength [Y(:,:,t), state] = modelDecoder(parameters,decoderInput,state); [~,idx] = max(Y(:,:,t)); decoderInput = idx; end
The output is a vocabularySize-by-miniBatchSize-by-sequenceLength array.
size(Y)
ans = 1×3
3595 32 16
This code snippet shows an example of performing closed loop generation in a model gradients function.
function [loss,gradients] = modelLoss(parameters,X,sequenceLengths) % Encode input. Z = modelEncoder(parameters,X,sequenceLengths); % Initialize LSTM state. state = struct; state.HiddenState = Z; state.CellState = zeros(size(Z),"like",Z); % Initialize decoder input. decoderInput = X(:,:,1); % Closed loop prediction. sequenceLength = size(X,3); Y = zeros(numClasses,miniBatchSize,sequenceLength,"like",X); for t = 1:sequenceLength [Y(:,:,t), state] = modelDecoder(parameters,decoderInput,state); [~,idx] = max(Y(:,:,t)); decoderInput = idx; end % Calculate loss. % ... % Calculate gradients. % ... end
Open Loop Generation: Teacher Forcing
When training with closed loop generation, predicting the most likely word for each step in the sequence can lead to suboptimal results. For example, in an image captioning workflow, if the decoder predicts the first word of a caption is "a" when given an image of an elephant, then the probability of predicting "elephant" for the next word becomes much more unlikely because of the extremely low probability of the phrase "a elephant" appearing in English text.
To help the network converge faster, you can use teacher forcing: use the target values as input to the decoder instead of the previous predictions. Using teacher forcing helps the network to learn characteristics from the later time steps of the sequences without having to wait for the network to correctly generate the earlier time steps of the sequences.
To perform teacher forcing, use the modelEncoder function directly with the target sequence as input.
Initialize the hidden state of the LSTM network with the encoder output Z.
state = struct;
state.HiddenState = Z;
state.CellState = zeros(size(Z),"like",Z);Make predictions using the target sequence as input.
Y = modelDecoder(parameters,X,state);
The output is a vocabularySize-by-miniBatchSize-by-sequenceLength array, where sequenceLength is the length of the input sequences.
size(Y)
ans = 1×3
3595 32 14
This code snippet shows an example of performing teacher forcing in a model gradients function.
function [loss,gradients] = modelLoss(parameters,X,sequenceLengths) % Encode input. Z = modelEncoder(parameters,X); % Initialize LSTM state. state = struct; state.HiddenState = Z; state.CellState = zeros(size(Z),"like",Z); % Teacher forcing. Y = modelDecoder(parameters,X,state); % Calculate loss. % ... % Calculate gradients. % ... end
Decoder Model Function
The modelDecoder function, takes as input the model parameters, sequences of word indices, and the network state, and returns the decoded sequences.
Because the lstm function is stateful (when given a time series as input, the function propagates and updates the state between each time step) and that the embed and fullyconnect functions are time-distributed by default (when given a time series as input, the functions operate on each time step independently), the modelDecoder function supports both sequence and single time-step inputs.
function [Y,state] = modelDecoder(parameters,X,state) % Embedding. weights = parameters.emb.Weights; X = embed(X,weights); % LSTM. inputWeights = parameters.lstmDecoder.InputWeights; recurrentWeights = parameters.lstmDecoder.RecurrentWeights; bias = parameters.lstmDecoder.Bias; hiddenState = state.HiddenState; cellState = state.CellState; [Y,hiddenState,cellState] = lstm(X,hiddenState,cellState, ... inputWeights,recurrentWeights,bias); state.HiddenState = hiddenState; state.CellState = cellState; % Fully connect. weights = parameters.fcDecoder.Weights; bias = parameters.fcDecoder.Bias; Y = fullyconnect(Y,weights,bias); end
See Also
dlfeval | dlgradient | dlarray