Train PPO Agent with Curriculum Learning for a Lane Keeping Application
This example shows how to use a curriculum to train a Proximal Policy Optimization (PPO) agent for Lane Keeping Assist (LKA) in Simulink®. A curriculum is a training strategy that begins with an easy task and gradually increases the task complexity to enhance the training efficiency of the agent. Task difficulty is controlled by the initial states and the curvature of the lane.
For more information on PPO agents, see Proximal Policy Optimization (PPO) Agent.
Open Simulink Model
The training goal for the lane keeping application is to keep the ego vehicle traveling along the centerline of a lane by adjusting the front steering angle. This example uses the same ego vehicle dynamics and sensor dynamics as the Train DQN Agent for Lane Keeping Assist example. Define the ego vehicle model parameters. The longitudinal distances of the front and rear tires are taken from the vehicle center of gravity (CG).
m = 1575; % Total vehicle mass (kg) Iz = 2875; % Yaw moment of inertia (mNs^2) lf = 1.2; % Longitudinal distance from CG to front tires (m) lr = 1.6; % Longitudinal distance from CG to rear tires (m) Cf = 19000; % Cornering stiffness of front tires (N/rad) Cr = 33000; % Cornering stiffness of rear tires (N/rad) Vx = 15; % Longitudinal velocity (m/s)
Define the sample time Ts and simulation duration T in seconds.
Ts = 0.1; T = 15;
The output of the LKA system is the front steering angle of the ego vehicle. Considering the physical limitations of the ego vehicle, constrain its steering angle to the range [-60,60] degrees. Specify the constraints in radians.
u_min = -1.04; u_max = 1.04;
Define the curvature of the road as a constant 0.001 .
rho = 0.001;
Set initial values for the lateral deviation (e1_initial) and the relative yaw angle (e2_initial). Before each training episode, the environment reset function sets these initial conditions to random values.
e1_initial = 0.2; e2_initial = -0.1;
Open the model.
mdl = "rlCurriculumLKAMdl";
open_system(mdl)
Define the path to the RL Agent block within the model.
agentblk = mdl + "/RL Agent";Fix Random Number Stream for Reproducibility
The example code might involve computation of random numbers at several stages. Fixing the random number stream at the beginning of some sections in the example code preserves the random number sequence in the section every time you run it, which increases the likelihood of reproducing the results. For more information, see Results Reproducibility.
Fix the random number stream with seed zero and random number algorithm Mersenne Twister. For more information on random number generation, see rng.
previousRngState = rng(0,"twister");The output previousRngState is a structure that contains information about the previous state of the stream. You will restore the state at the end of the example.
Create Environment
Create a reinforcement learning environment object for the ego vehicle. First define the observation and action specifications. These observations and actions are the same as the features for supervised learning used in Imitate MPC Controller for Lane Keeping Assist.
The six observations for the environment are:
the lateral velocity ,
the yaw rate ,
the lateral deviation ,
the relative yaw angle ,
the steering angle at previous step ,
the curvature .
obsInfo = rlNumericSpec([6 1], ... LowerLimit=-inf*ones(6,1), ... UpperLimit=inf*ones(6,1))
obsInfo =
rlNumericSpec with properties:
LowerLimit: [6×1 double]
UpperLimit: [6×1 double]
Name: [0×0 string]
Description: [0×0 string]
Dimension: [6 1]
DataType: "double"
obsInfo.Name = "observations";The action for the environment is the front steering angle. Specify the steering angle constraints when creating the action specification object.
actInfo = rlNumericSpec([1 1], ... LowerLimit=u_min, ... UpperLimit=u_max); actInfo.Name = "steering";
In the model, the Signal Processing for LKA block creates the observation vector signal, computes the reward function, and calculates the stop signal.
In this example, the reward , provided at every time step , consists of a cost, a penalty for the terminal condition, and an incentive to keep the lateral error within a threshold.
Here, is the control input from the previous time step .
The simulation stops when .
Create the reinforcement learning environment.
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);
To define the initial condition for lateral deviation and relative yaw angle, specify an environment reset function. The localResetFcn function, which is defined at the end of the example, sets the initial lateral deviation and relative yaw angle to random values depending on the task number. Each subsequent task becomes more difficult.
Task 1: Straight road, starting with small errors
Task 2: Road with small curvature, starting with relatively small errors
Task 3: Road with large curvature, starting with relatively large errors (final task)
Create PPO Agent
Fix the random generator seed for reproducibility.
rng(0,"twister")Create a PPO agent.
initOptions = rlAgentInitializationOptions("NumHiddenUnit",256);
agentNoCrm = rlPPOAgent(obsInfo,actInfo,initOptions);Specify the PPO agent options.
agentNoCrm.AgentOptions.MiniBatchSize = 512; agentNoCrm.AgentOptions.LearningFrequency = 4096; agentNoCrm.AgentOptions.ActorOptimizerOptions.LearnRate = 5e-4; agentNoCrm.AgentOptions.ActorOptimizerOptions.GradientThreshold = 5; agentNoCrm.AgentOptions.CriticOptimizerOptions.LearnRate = 5e-4; agentNoCrm.AgentOptions.CriticOptimizerOptions.GradientThreshold = 5; agentNoCrm.AgentOptions.SampleTime = Ts;
Train Agent Without a Curriculum
As a baseline, train the agent for task 3 without a curriculum. Specify a reset function that calls localResetFcn function, using an anonymous function handle. This syntax allows you to set taskNumber to 3 in the called function while using only one input argument for env.ResetFcn.
taskNumber = 3; env.ResetFcn = @(in)localResetFcn(in,taskNumber);
To train the agent, first specify the training options.
Run training for a maximum of 50,000 episodes, with each episode lasting a maximum of 150 time steps.
Display the training progress in the Reinforcement Learning Training Monitor.
Stop the training when the evaluation statistic (mean of evaluation episode rewards) is 2.9. The training function evaluates the agent with 10 evaluation episodes at every 100 training episodes.
For more information on training options, see rlTrainingOptions.
maxepisodes = 50000; maxsteps = T/Ts; trainingOpts = rlTrainingOptions( ... MaxEpisodes=maxepisodes, ... MaxStepsPerEpisode=maxsteps, ... Verbose=false, ... Plots="training-progress", ... StopTrainingCriteria="EvaluationStatistic", ... StopTrainingValue=2.9); % Create an evaluator object. evl = rlEvaluator( ... NumEpisodes=10, ... EvaluationFrequency=100, ... RandomSeeds=101:110);
Train the agent using the train function. The training process is computationally intensive and takes several hours to complete. To save time while running this example, load a pretrained agent by setting doTrainingWithoutCurriculum to false. To train the agent yourself, set doTrainingWithoutCurriculum to true.
doTrainingWithoutCurriculum =false; if doTrainingWithoutCurriculum % Train the agent without a curriculum. trainingStats = train(agentNoCrm,env,trainingOpts,Evaluator=evl); end

Train Agent with a Curriculum
Curriculum learning starts with simpler tasks and gradually increases the complexity to train the agent more efficiently. The following example sections train the agent with two simple tasks and then completes the training with a more complex final task.
Create PPO Agent
Fix the random generator seed for reproducibility.
rng(0,"twister")Create a PPO agent.
initOptions = rlAgentInitializationOptions("NumHiddenUnit",256);
agent = rlPPOAgent(obsInfo,actInfo,initOptions);
agent.AgentOptions.SampleTime = Ts;
agent.AgentOptions.MiniBatchSize = 512;
agent.AgentOptions.ActorOptimizerOptions.GradientThreshold = 5;
agent.AgentOptions.CriticOptimizerOptions.GradientThreshold = 5;Train the agent using the train function. The training process is computationally intensive and takes several hours to complete. To save time while running this example, load a pretrained agent by setting doTraining to false. To train the agent yourself, set doTraining to true.
doTraining =  false;
false;Task 1: Straight road, starting with small errors.
Set the task to 1, the max number of episodes to 3000, and the stop the training value to 2.5. Redefine the reset function to use the new task number in the anonymous function workspace.
taskNumber = 1; env.ResetFcn = @(in)localResetFcn(in,taskNumber); trainingOpts.MaxEpisodes = 3000; trainingOpts.StopTrainingValue = 2.5;
Specify the PPO agent options for task 1. To achieve a faster learning, set a greater LearnRate in the initial task. A larger LearnRate might cause issues with convergence. However, the goal is to train the agent in the final task, so it is not necessary to fine-tune the agent in the initial task. To update the agent more often in task 1, set LearningFrequency to 1024.
agent.AgentOptions.LearningFrequency = 1024; agent.AgentOptions.ActorOptimizerOptions.LearnRate = 1e-3; agent.AgentOptions.CriticOptimizerOptions.LearnRate = 1e-3;
Train the PPO agent.
if doTraining trainingStats1 = train(agent,env,trainingOpts,Evaluator=evl); end

Task 2: Road with small curvature, starting with relatively small errors.
Set the task to 2, the max number of episodes to 3000, and the stop the training value to 2.5. Redefine the reset function to use the new task number in the anonymous function workspace.
taskNumber = 2; env.ResetFcn = @(in)localResetFcn(in,taskNumber); trainingOpts.MaxEpisodes = 3000; trainingOpts.StopTrainingValue = 2.5;
Specify the PPO agent options. To collect more trajectories before each update of the learnable parameters, set LearningFrequency to 2048.
agent.AgentOptions.LearningFrequency = 2048;
Train the PPO agent.
if doTraining trainingStats2 = train(agent,env,trainingOpts,Evaluator=evl); end
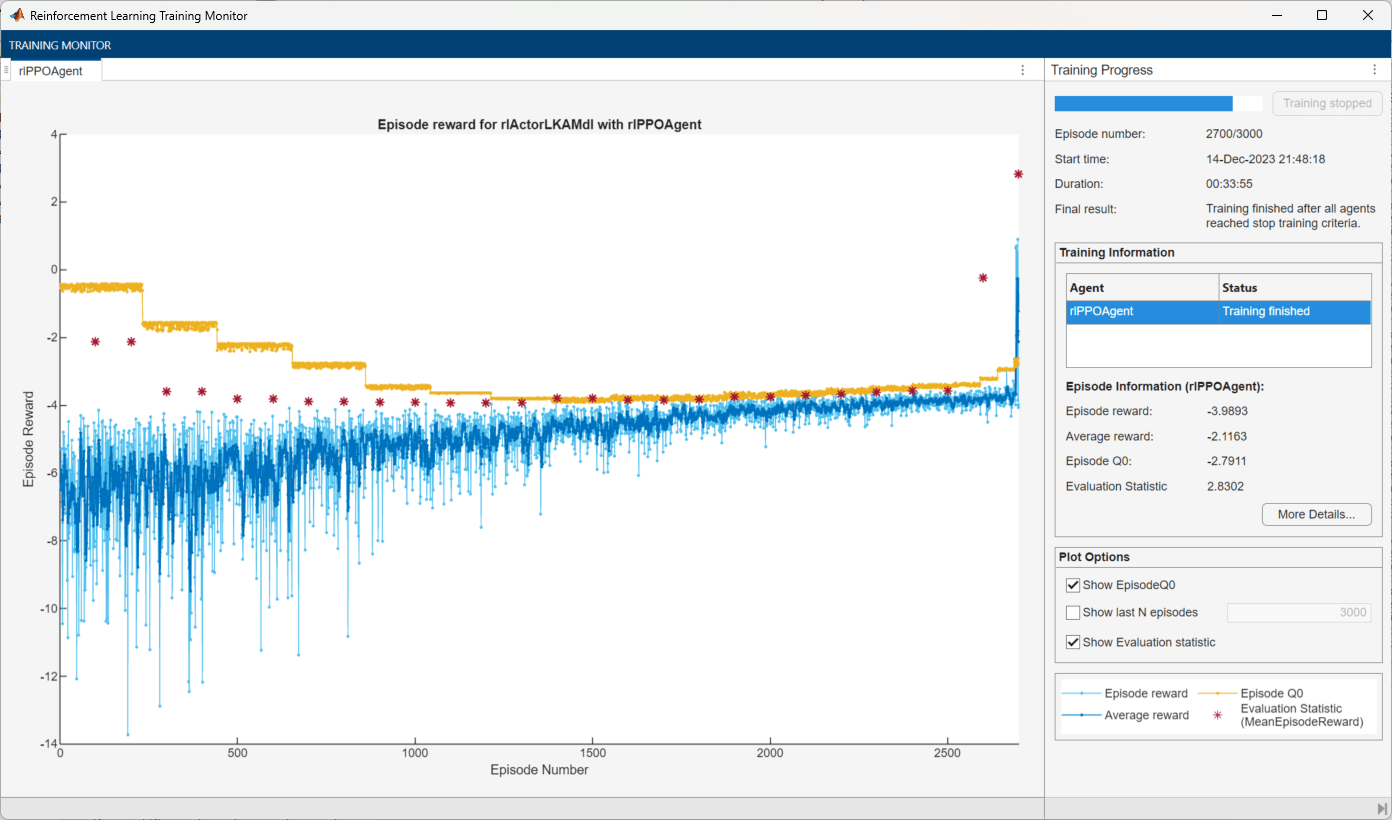
Task 3: Road with large curvature, starting with relatively large errors (final task)
Set the task to 3, the max number of episode to 50,000, and the stop the training value to 2.9. Redefine the reset function to use the new task number in the anonymous function workspace.
taskNumber = 3; env.ResetFcn = @(in)localResetFcn(in,taskNumber); trainingOpts.MaxEpisodes = 50000; trainingOpts.StopTrainingValue = 2.9;
Specify the PPO agent options to match those used for the agent trained without a curriculum.
agent.AgentOptions.LearningFrequency = 4096; agent.AgentOptions.ActorOptimizerOptions.LearnRate = 5e-4; agent.AgentOptions.CriticOptimizerOptions.LearnRate = 5e-4;
Train the PPO agent.
if doTraining trainingStats3 = train(agent,env,trainingOpts,Evaluator=evl); else load("LKAPPOAgent.mat") end
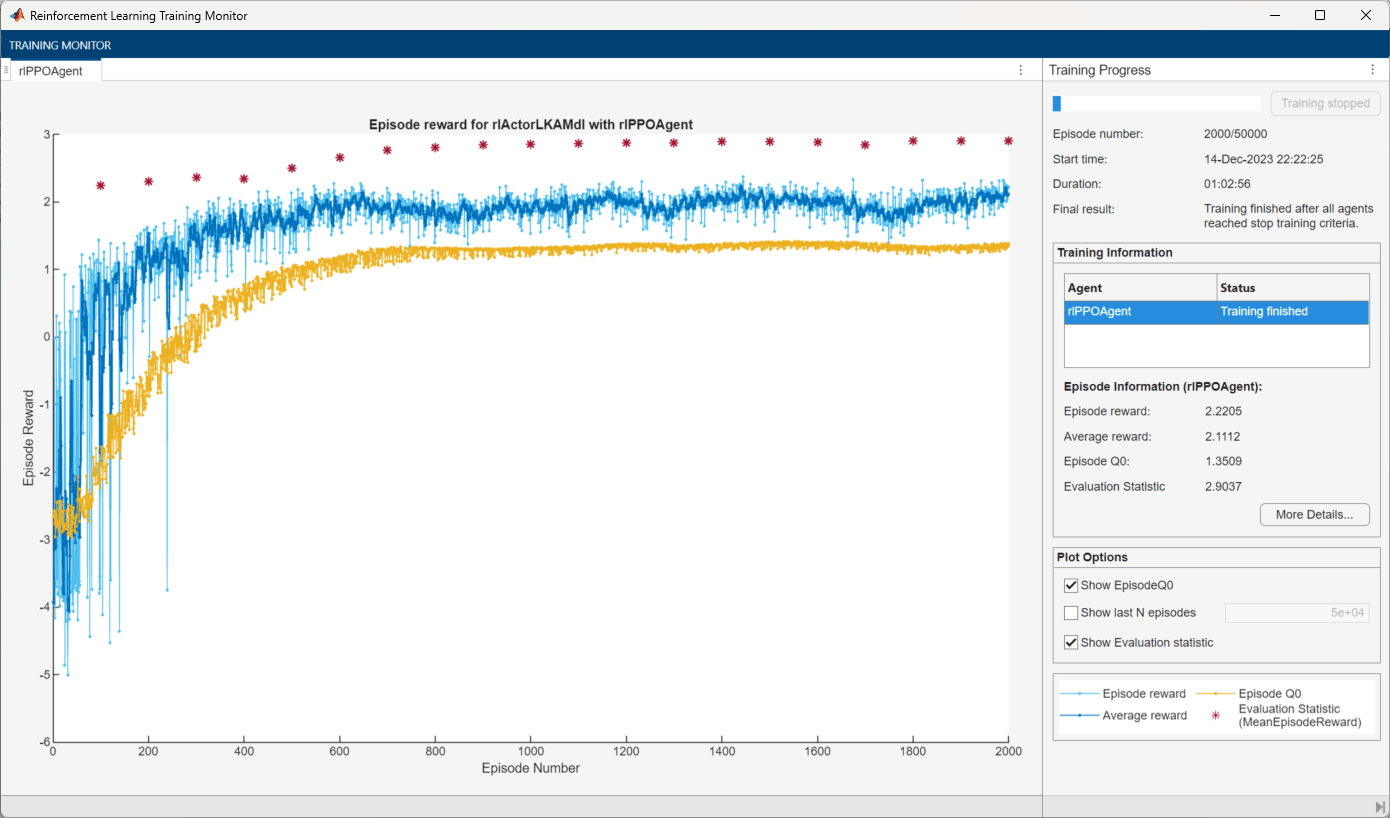
The PPO agent trained with a curriculum meets the criteria after 5000 total episodes: 300 episodes in task 1, 2700 episodes in task 2, and 2000 episodes in task 3. In contrast, the agent trained without a curriculum requires 8300 episodes to meet the criteria. The training time is shorter with curriculum learning compared to the noncurriculum approach.
Simulate Trained PPO Agent
To validate the performance of the trained agent, simulate it within the environment. For more information on agent simulation, see rlSimulationOptions and sim.
% Create simulation options object simOptions = rlSimulationOptions(MaxSteps=maxsteps); % Set the task number to 4 to evaluate the agent with a specific % initial condition. The curvature is the same as in task 3. taskNumber = 4; env.ResetFcn = @(in)localResetFcn(in,taskNumber); % Simulate the agent. experience = sim(env,agent,simOptions);



The lateral error and the yaw error both approach zero, as shown in the respective plots. The vehicle starts with a lateral deviation from the centerline (0.2 m) and a nonzero yaw angle error (–0.1 rad). The lane keeping controller makes the ego vehicle travel along the centerline after approximately two seconds. The steering angle shows that the controller reaches a steady state within the same time frame. The steering angle also achieves a steady state after approximately two seconds.
Restore the random number stream using the information stored in previousRngState.
rng(previousRngState);
Local Reset Function
The sim function calls the reset function at the start of each simulation episode, and the train function calls it at the start of each training episode. The reset function takes as input, and returns as output, a Simulink.SimulationInput (Simulink) object. The output object specifies temporary changes applied to model, which are then discarded when the simulation or training completes. For this example, the reset function uses the setVariable (Simulink) function to specify random values for the initial lateral deviation and relative yaw angle in the model workspace, depending on the task number. For more information, see Reset Function for Simulink Environments.
function in = localResetFcn(in,taskNumber) switch taskNumber case 1 % Task 1: Straight road, % starting with small errors. e1_initial = 0.05*(-1+2*rand); e2_initial = 0.01*(-1+2*rand); rho = 0; case 2 % Task 2: Road with small curvature, % starting with relatively small errors. e1_initial = 0.25*(-1+2*rand); e2_initial = 0.05*(-1+2*rand); rho = 0.0005; case 3 % Task 3 : Road with large curvature, starting % with relatively large errors (final task) e1_initial = 0.5*(-1+2*rand); e2_initial = 0.1*(-1+2*rand); rho = 0.001; case 4 % Final simulation purpose. e1_initial = 0.2; e2_initial = -0.1; rho = 0.001; end % Set random value for lateral deviation. in = setVariable(in,"e1_initial",e1_initial); % Set random value for relative yaw angle. in = setVariable(in,"e2_initial",e2_initial); % Set curvature in = setVariable(in,"rho",rho); end
See Also
Functions
train|sim|rlSimulinkEnv
Objects
rlPPOAgent|rlPPOAgentOptions|rlAgentInitializationOptions|rlTrainingOptions|rlOptimizerOptions|rlSimulationOptions