canoncorr
Canonical correlation
Syntax
Description
Examples
Perform canonical correlation analysis for a sample data set.
The data set carbig contains measurements for 406 cars from the years 1970 to 1982.
Load the sample data.
load carbig;
data = [Displacement Horsepower Weight Acceleration MPG];Define X as the matrix of displacement, horsepower, and weight observations, and Y as the matrix of acceleration and MPG observations. Omit rows with insufficient data.
nans = sum(isnan(data),2) > 0; X = data(~nans,1:3); Y = data(~nans,4:5);
Compute the sample canonical correlation.
[A,B,r,U,V] = canoncorr(X,Y);
View the output of A to determine the linear combinations of displacement, horsepower, and weight that make up the canonical variables of X.
A
A = 3×2
0.0025 0.0048
0.0202 0.0409
-0.0000 -0.0027
A(3,1) is displayed as —0.000 because it is very small. Display A(3,1) separately.
A(3,1)
ans = -2.4737e-05
The first canonical variable of X is u1 = 0.0025*Disp + 0.0202*HP — 0.000025*Wgt.
The second canonical variable of X is u2 = 0.0048*Disp + 0.0409*HP — 0.0027*Wgt.
View the output of B to determine the linear combinations of acceleration and MPG that make up the canonical variables of Y.
B
B = 2×2
-0.1666 -0.3637
-0.0916 0.1078
The first canonical variable of Y is v1 = —0.1666*Accel — 0.0916*MPG.
The second canonical variable of Y is v2 = —0.3637*Accel + 0.1078*MPG.
Plot the scores of the canonical variables of X and Y against each other.
t = tiledlayout(2,2); title(t,'Canonical Scores of X vs Canonical Scores of Y') xlabel(t,'Canonical Variables of X') ylabel(t,'Canonical Variables of Y') t.TileSpacing = 'compact'; nexttile plot(U(:,1),V(:,1),'.') xlabel('u1') ylabel('v1') nexttile plot(U(:,2),V(:,1),'.') xlabel('u2') ylabel('v1') nexttile plot(U(:,1),V(:,2),'.') xlabel('u1') ylabel('v2') nexttile plot(U(:,2),V(:,2),'.') xlabel('u2') ylabel('v2')
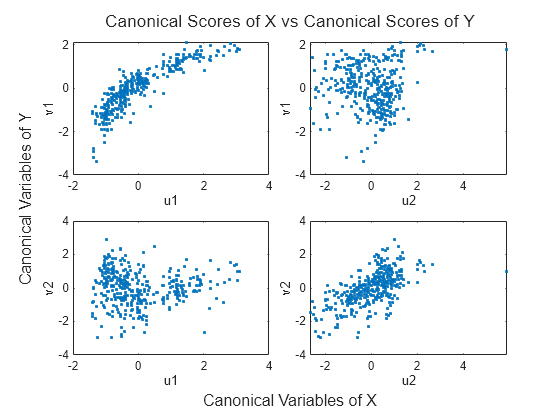
The pairs of canonical variables are ordered from the strongest to weakest correlation, with all other pairs independent.
Return the correlation coefficient of the variables u1 and v1.
r(1)
ans = 0.8782
Input Arguments
Output Arguments
More About
Algorithms
canoncorr computes A, B,
and r using qr and svd. canoncorr computes U and
V as U = (X—mean(X))*A and V =
(Y—mean(Y))*B.
References
[1] Krzanowski, W. J. Principles of Multivariate Analysis: A User's Perspective. New York: Oxford University Press, 1988.
[2] Seber, G. A. F. Multivariate Observations. Hoboken, NJ: John Wiley & Sons, Inc., 1984.
Version History
Introduced before R2006a