manova1
One-way multivariate analysis of variance (MANOVA)
Description
Examples
Load the carbig data set.
load carbigCalculate the dimension of the space containing the group mean vectors and the corresponding p-values.
[d,p] = manova1([MPG Acceleration Weight Displacement],...
Origin)d = 3
p = 4×1
0.0000
0.0000
0.0075
0.1934
The output shows that enough evidence exists to reject the null hypothesis that the mean vectors are statistically the same. However, not enough evidence exists to reject the null hypothesis that the mean vectors lie in the same 3D space.
Load the fisheriris data set.
load fisheriris;The column vector species contains three iris flower species: setosa, versicolor, and virginica. The matrix meas contains four types of measurements for the flower: the length and width of sepals and petals in centimeters.
Perform a one-way MANOVA to test the null hypothesis that the vector of means for the four measurements is the same across the three flower species. Specify the significance level. Calculate the dimension of the space containing the vectors for the three flower species, the corresponding p-values, and additional statistics for the MANOVA.
[d,p,stats] = manova1(meas,species,0.01)
d = 2
p = 2×1
10-7 ×
0.0000
0.5786
stats = struct with fields:
W: [4×4 double]
B: [4×4 double]
T: [4×4 double]
dfW: 147
dfB: 2
dfT: 149
lambda: [2×1 double]
chisq: [2×1 double]
chisqdf: [2×1 double]
eigenval: [4×1 double]
eigenvec: [4×4 double]
canon: [150×4 double]
mdist: [150×1 double]
gmdist: [3×3 double]
gnames: {3×1 cell}
The output shows that the vectors of means for the three species are contained in a two-dimensional space. This result indicates that one of the vectors is statistically different from the others. The stats structure contains additional statistics for the MANOVA.
Inspect the canonical response data for the MANOVA.
C = stats.canon
C = 150×4
-8.0618 0.3004 0.1583 -0.2290
-7.1287 -0.7867 0.7466 0.4909
-7.4898 -0.2654 -0.0957 0.5471
-6.8132 -0.6706 -0.6908 0.4402
-8.1323 0.5145 -0.3944 -0.2742
-7.7019 1.4617 -0.1331 -0.6035
-7.2126 0.3558 -0.8867 0.6096
-7.6053 -0.0116 -0.1736 -0.1893
-6.5606 -1.0152 -0.5653 0.9595
-7.3431 -0.9473 -0.0253 -0.1415
-8.3974 0.6474 0.3436 -0.8188
-7.2193 -0.1096 -1.0583 -0.1948
-7.3268 -1.0730 0.1690 0.1914
-7.5725 -0.8055 -0.5953 0.9841
-9.8498 1.5859 1.6503 -1.0085
⋮
Each column of C corresponds to a canonical variable, and each row contains a transformed data point corresponding to the same row in X. For more information about canonical variables, see Canonical Variables.
Create a scatter plot using the first and second canonical variables.
gscatter(C(:,1),C(:,2),species)
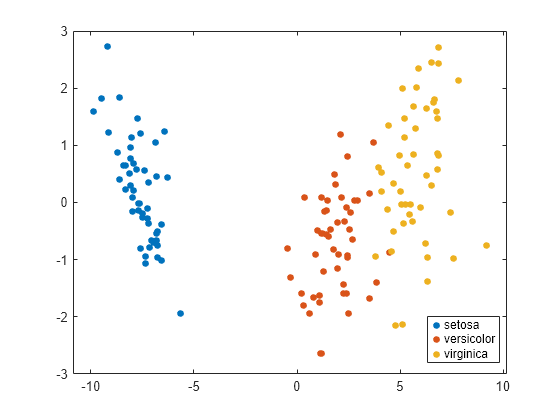
The scatter plot shows two main clusters of data, with the measurements for setosa in one cluster and the measurements for versicolor and virginica in the other. This result also shows that the vectors of means for the three species are contained in a two-dimensional space.
Input Arguments
Output Arguments
More About
Algorithms
manova1 determines d by calculating a test
statistic for each possible value of d. The formula for the test
statistic is
where n is the number of observations, l is the number of factor levels, r is the number of response variables, and is Wilks' lambda. For more information about Wilks' lambda, see Multivariate Analysis of Variance for Repeated Measures.
The largest possible value of d is the minimum between the number of
response variables and one less than the number of factor levels. d is
the largest value for which the p-value is less than the significance
level specified by alpha.
Alternative Functionality
Instead of using manova1, you can create a
manova object using the manova function,
and then use the barttest object
function to calculate the dimension of the space containing the group means. The advantages of
using the manova function include:
Support for two-way and N-way MANOVA
Table support for factor and response data
Additional properties of the
manovaobject, including those for the fitted MANOVA model coefficients, degrees of freedom for the error, and response covariance matrix
References
[1] Krzanowski, Wojtek. J. Principles of Multivariate Analysis: A User's Perspective. New York: Oxford University Press, 1988.
[2] Morrison, Donald F. Multivariate Statistical Methods. 2nd ed, McGraw-Hill, 1976.
Version History
Introduced before R2006a