fscmrmr
Rank features for classification using minimum redundancy maximum relevance (MRMR) algorithm
Syntax
Description
fscmrmr ranks features (predictors) using the MRMR algorithm to
identify important predictors for classification problems.
To perform MRMR-based feature ranking for regression, see fsrmrmr.
idx = fscmrmr(Tbl,ResponseVarName)idx, ordered by predictor importance
(from most important to least important). The table Tbl contains the
predictor variables and a response variable, ResponseVarName, which
contains the class labels. You can use idx to select important
predictors for classification problems.
idx = fscmrmr(___,Name,Value)
Examples
Load the sample data.
load ionosphereRank the predictors based on importance.
[idx,scores] = fscmrmr(X,Y);
Create a bar plot of the predictor importance scores.
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score')

The drop in score between the first and second most important predictors is large, while the drops after the sixth predictor are relatively small. A drop in the importance score represents the confidence of feature selection. Therefore, the large drop implies that the software is confident of selecting the most important predictor. The small drops indicate that the difference in predictor importance are not significant.
Select the top five most important predictors. Find the columns of these predictors in X.
idx(1:5)
ans = 1×5
5 4 1 7 24
The fifth column of X is the most important predictor of Y.
Find important predictors by using fscmrmr. Then compare the accuracies of the full classification model (which uses all the predictors) and a reduced model that uses the five most important predictors by using testckfold.
Load the census1994 data set.
load census1994The table adultdata in census1994 contains demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year. Display the first three rows of the table.
head(adultdata,3)
age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
The output arguments of fscmrmr include only the variables ranked by the function. Before passing a table to the function, move the variables that you do not want to rank, including the response variable and weight, to the end of the table so that the order of the output arguments is consistent with the order of the table.
In the table adultdata, the third column fnlwgt is the weight of the samples, and the last column salary is the response variable. Move fnlwgt to the left of salary by using the movevars function.
adultdata = movevars(adultdata,'fnlwgt','before','salary'); head(adultdata,3)
age workClass education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country fnlwgt salary
___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______
39 State-gov Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States 77516 <=50K
50 Self-emp-not-inc Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States 83311 <=50K
38 Private HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States 2.1565e+05 <=50K
Rank the predictors in adultdata. Specify the column salary as the response variable.
[idx,scores] = fscmrmr(adultdata,'salary','Weights','fnlwgt');
Create a bar plot of predictor importance scores. Use the predictor names for the x-axis tick labels.
bar(scores(idx)) xlabel('Predictor rank') ylabel('Predictor importance score') xticklabels(strrep(adultdata.Properties.VariableNames(idx),'_','\_')) xtickangle(45)
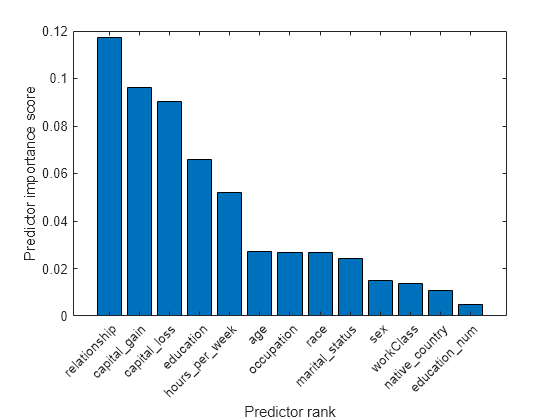
The five most important predictors are relationship, capital_loss, capital_gain, education, and hours_per_week.
Compare the accuracy of a classification tree trained with all predictors to the accuracy of one trained with the five most important predictors.
Create a classification tree template using the default options.
C = templateTree;
Define the table tbl1 to contain all predictors and the table tbl2 to contain the five most important predictors.
tbl1 = adultdata(:,adultdata.Properties.VariableNames(idx(1:13))); tbl2 = adultdata(:,adultdata.Properties.VariableNames(idx(1:5)));
Pass the classification tree template and the two tables to the testckfold function. The function compares the accuracies of the two models by repeated cross-validation. Specify 'Alternative','greater' to test the null hypothesis that the model with all predictors is, at most, as accurate as the model with the five predictors. The 'greater' option is available when 'Test' is '5x2t' (5-by-2 paired t test) or '10x10t' (10-by-10 repeated cross-validation t test).
[h,p] = testckfold(C,C,tbl1,tbl2,adultdata.salary,'Weights',adultdata.fnlwgt,'Alternative','greater','Test','5x2t')
h = logical
0
p = 0.9970
h equals 0 and the p-value is almost 1, indicating failure to reject the null hypothesis. Using the model with the five predictors does not result in loss of accuracy compared to the model with all the predictors.
Now train a classification tree using the selected predictors.
mdl = fitctree(adultdata,'salary ~ relationship + capital_loss + capital_gain + education + hours_per_week', ... 'Weights',adultdata.fnlwgt)
mdl =
ClassificationTree
PredictorNames: {'education' 'relationship' 'capital_gain' 'capital_loss' 'hours_per_week'}
ResponseName: 'salary'
CategoricalPredictors: [1 2]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
Properties, Methods
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Ding, C., and H. Peng. "Minimum redundancy feature selection from microarray gene expression data." Journal of Bioinformatics and Computational Biology. Vol. 3, Number 2, 2005, pp. 185–205.
[2] Darbellay, G. A., and I. Vajda. "Estimation of the information by an adaptive partitioning of the observation space." IEEE Transactions on Information Theory. Vol. 45, Number 4, 1999, pp. 1315–1321.