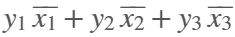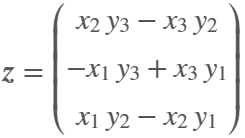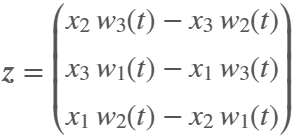figure('Color', 'k', 'Position', [100, 100, 800, 800]);
ax = axes('Color', 'k', 'XColor', 'none', 'YColor', 'none', 'ZColor', 'none');
color_data = rescale(lat, 0.3, 0.9);
planet = surf(x*saturn_radius, y*saturn_radius, z*saturn_radius, ...
'FaceColor', 'interp', ...
'FaceLighting', 'gouraud', ...
'AmbientStrength', 0.3, ...
'DiffuseStrength', 0.6, ...
'SpecularStrength', 0.1);
cream_map = [linspace(0.4, 0.95, 256)', ...
linspace(0.35, 0.9, 256)', ...
linspace(0.2, 0.7, 256)'];
theta = linspace(0, 2*pi, n_points);
brightness = rings(i, 3);
x_inner = r_inner * cos(theta);
y_inner = r_inner * sin(theta);
x_outer = r_outer * cos(theta);
y_outer = r_outer * sin(theta);
ring_x = [x_inner, fliplr(x_outer)];
ring_y = [y_inner, fliplr(y_outer)];
ring_z = zeros(size(ring_x));
ring_color = brightness * [0.9, 0.85, 0.7];
fill3(ring_x, ring_y, ring_z, ring_color, ...
'FaceLighting', 'gouraud', ...
r_particles = 1.2 + rand(1, n_particles) * 1.6;
theta_particles = rand(1, n_particles) * 2 * pi;
x_particles = r_particles .* cos(theta_particles);
y_particles = r_particles .* sin(theta_particles);
z_particles = (rand(1, n_particles) - 0.5) * 0.02;
particle_colors = repmat([0.8, 0.75, 0.6], n_particles, 1) .* ...
(0.5 + 0.5*rand(n_particles, 1));
scatter3(x_particles, y_particles, z_particles, 1, particle_colors, ...
'filled', 'MarkerFaceAlpha', 0.3);
glow_radius = 1 + i*0.35;
alpha_val = 0.08 / sqrt(i);
glow_color = [0.9, 0.85, 0.7];
mix = (i - 8) / (n_glow - 8);
glow_color = (1-mix)*[0.9, 0.85, 0.7] + mix*[0.6, 0.65, 0.85];
surf(x*glow_radius, y*glow_radius, z*glow_radius, ...
'FaceColor', glow_color, ...
'FaceAlpha', alpha_val, ...
alpha_ring = 0.12 / sqrt(i);
r_inner = rings(j, 1) * glow_scale;
r_outer = rings(j, 2) * glow_scale;
brightness = rings(j, 3) * 0.5 / sqrt(i);
x_inner = r_inner * cos(theta);
y_inner = r_inner * sin(theta);
x_outer = r_outer * cos(theta);
y_outer = r_outer * sin(theta);
ring_x = [x_inner, fliplr(x_outer)];
ring_y = [y_inner, fliplr(y_outer)];
ring_z = zeros(size(ring_x));
ring_color = brightness * [0.9, 0.85, 0.7];
mix = (i - 6) / (n_ring_glow - 6);
ring_color = brightness * ((1-mix)*[0.9, 0.85, 0.7] + mix*[0.65, 0.7, 0.9]);
fill3(ring_x, ring_y, ring_z, ring_color, ...
'FaceAlpha', alpha_ring, ...
glow_radius_particles = 1.5 + rand(1, n_glow_particles) * 5;
theta_glow = rand(1, n_glow_particles) * 2 * pi;
phi_glow = acos(2*rand(1, n_glow_particles) - 1);
x_glow = glow_radius_particles .* sin(phi_glow) .* cos(theta_glow);
y_glow = glow_radius_particles .* sin(phi_glow) .* sin(theta_glow);
z_glow = glow_radius_particles .* cos(phi_glow);
particle_glow_colors = zeros(n_glow_particles, 3);
for i = 1:n_glow_particles
dist = glow_radius_particles(i);
particle_glow_colors(i,:) = [0.9, 0.85, 0.7];
particle_glow_colors(i,:) = (1-mix)*[0.9, 0.85, 0.7] + mix*[0.5, 0.6, 0.9];
scatter3(x_glow, y_glow, z_glow, rand(1, n_glow_particles)*2+0.5, ...
particle_glow_colors, 'filled', 'MarkerFaceAlpha', 0.05);
light('Position', [-3, -2, 4], 'Style', 'infinite', ...
light('Position', [2, 3, 2], 'Style', 'infinite', ...
'Color', [0.3, 0.3, 0.4]);
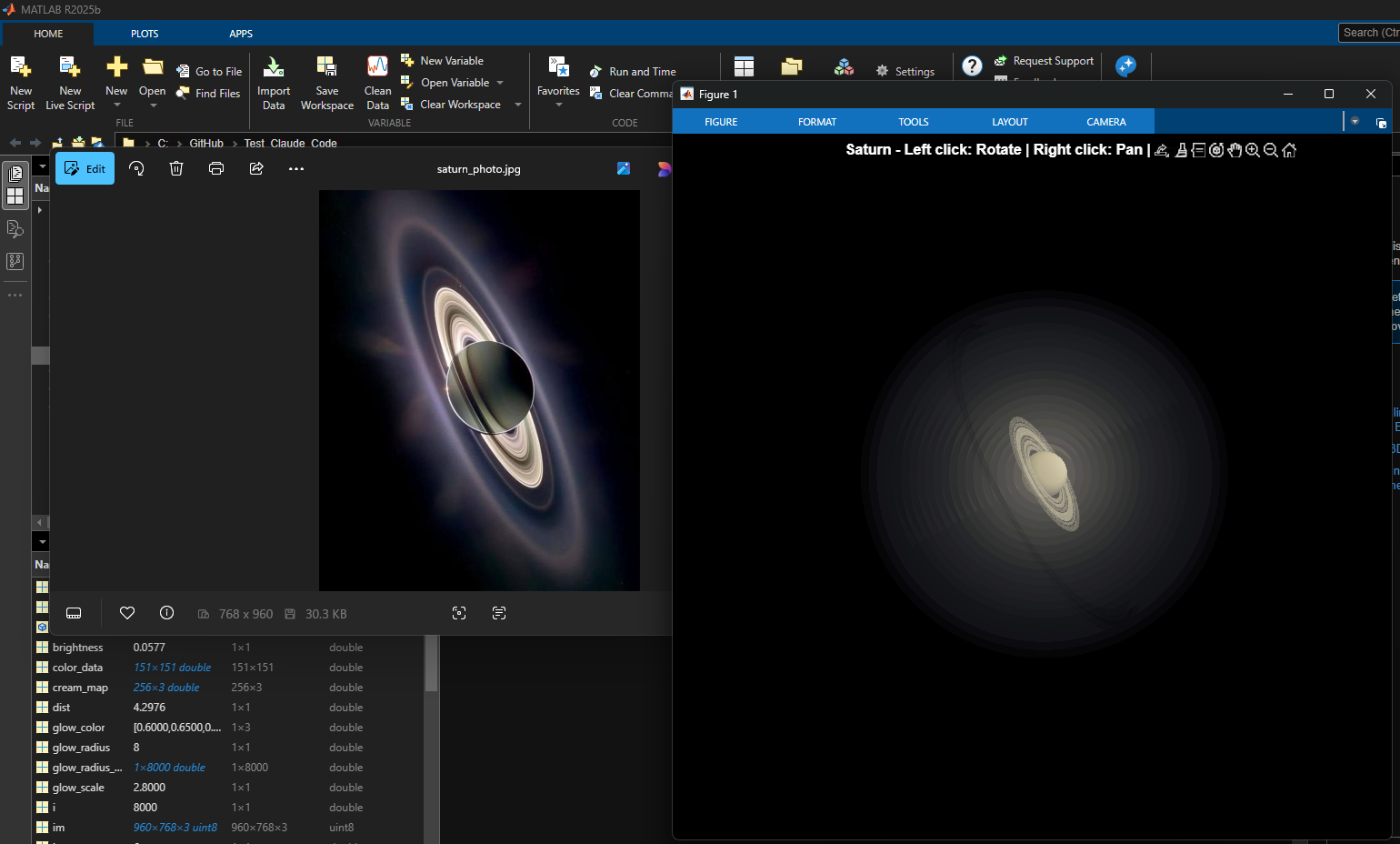
title('Saturn - Left click: Rotate | Right click: Pan | Scroll: Zoom', 'Color', 'w', 'FontSize', 12);
cameratoolbar('SetMode', 'orbit');
set(gcf, 'WindowButtonDownFcn', @mouseDown);
function mouseDown(src, ~)
selType = get(src, 'SelectionType');
cameratoolbar('SetMode', 'orbit');
cameratoolbar('SetMode', 'pan');