detect
Detect objects using SSD object detector configured for monocular camera
Syntax
Description
bboxes = detect(detector,I)I using an SSD (singe shot detection
convolutional neural networks) multibox object detector configured for a monocular camera.
The locations of objects detected are returned as a set of bounding boxes.
When using this function, use of a CUDA®-enabled NVIDIA® GPU. The GPU reduces computation time significantly. Usage of the GPU requires Parallel Computing Toolbox™. For information about the supported compute capabilities, see GPU Computing Requirements (Parallel Computing Toolbox).
[___,
also returns a categorical array of labels assigned to the bounding boxes, using either of
the preceding syntaxes. The labels used for object classes are defined during training
using the labels] = detect(detector,I)trainSSDObjectDetector function.
[___] = detect(___,
detects objects within the rectangular search region specified by
roi)roi. Use output arguments from any of the previous syntaxes. Specify
input arguments from any of the previous syntaxes.
detectionResults = detect(detector,ds)read function
of the input datastore.
[___] = detect(___,
specifies options using one or more Name,Value)Name,Value pair arguments. For
example, detect(detector,I,'Threshold',0.75) sets the detection score
threshold to 0.75. Any detections with a lower score are
removed.
Examples
Configure an SSD object detector for use with a monocular camera mounted on an ego vehicle. Use this detector to detect vehicles within an image captured by the camera.
Load an ssdObjectDetector object pretrained to detect vehicles.
vehicleDetector = load('ssdVehicleDetector.mat','detector'); detector = vehicleDetector.detector;
Model a monocular camera sensor by creating a monoCamera object. This object contains the camera intrinsics and the location of the camera on the ego vehicle.
focalLength = [309.4362 344.2161]; % [fx fy] principalPoint = [318.9034 257.5352]; % [cx cy] imageSize = [480 640]; % [mrows ncols] height = 2.1798; % height of camera above ground, in meters pitch = 14; % pitch of camera, in degrees intrinsics = cameraIntrinsics(focalLength,principalPoint,imageSize); sensor = monoCamera(intrinsics,height,'Pitch',pitch);
Configure the detector for use with the camera. Limit the width of detected objects to 1.5 – 2.5 meters. The configured detector is an ssdObjectDetectorMonoCamera object.
vehicleWidth = [1.5 2.5]; detectorMonoCam = configureDetectorMonoCamera(detector,sensor,vehicleWidth);
Read an image captured by the camera.
I = imread('highwayCars.png');Detect the vehicles in the image by using the detector. Annotate the image with the bounding boxes for the detections and the detection confidence scores.
[bboxes,scores,labels] = detect(detectorMonoCam,I,'Threshold',0.6); I = insertObjectAnnotation(I,'rectangle',bboxes,scores,'AnnotationColor','g'); imshow(I)
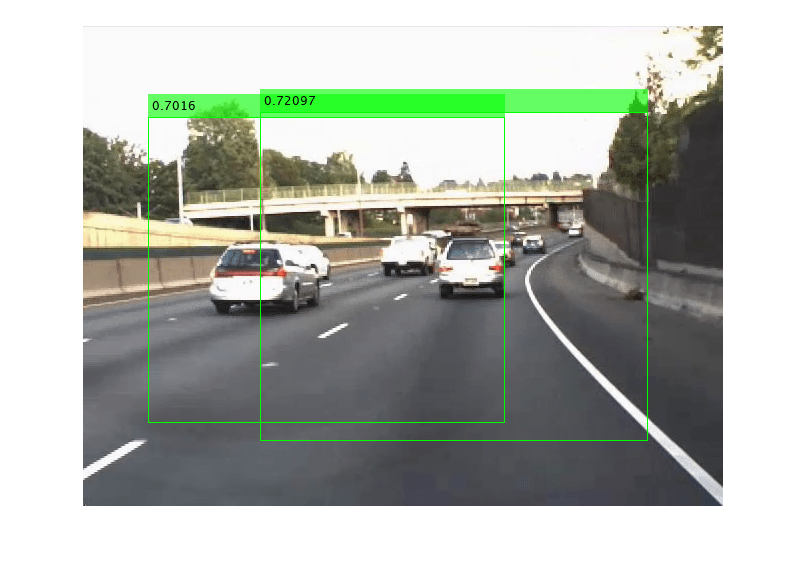
Display the labels for detected bounding boxes. The labels specify the class names of the detected objects.
disp(labels)
vehicle
vehicle
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2020a
See Also
Apps
Functions
configureDetectorMonoCamera|selectStrongestBboxMulticlass|evaluateDetectionMissRate|evaluateDetectionPrecision
Objects
Topics
- Object Detection Using SSD Deep Learning
- Datastores for Deep Learning (Deep Learning Toolbox)